13_Visualization_Anscombe
import warnings
warnings.filterwarnings('ignore')
from IPython.display import Image
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt #그래프
import seaborn as sns
import matplotlib as mpl
#한글 폰트를 사용할 때 마이너스 데이터가 깨져
#보이는 문제를 해결한다.
mpl.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'NanumGothicCoding'
plt.rcParams['font.size'] = 15
#사람의 눈은 수백 줄의 텍스트만으로 이루어진 데이터를
#읽거나 기초 통계 수치를 계산하는 방법으로는 데이터를
#제데로 분석할 수 없기 때문에, 데이터에 숨겨진 패턴을
#파악하기 위해 데이터 시각화를 사용한다.
#엔스콤 4분할 그래프
#데이터를 시각화하지 않고 수치만 확인햇을 때 발생할 수
#있는 함정을 보여주기 위해 만든 그래프
#데이터 집합은 4개의 그룹으로 구성되어 있으며 4개의 데이터
#그룹은 각각 평균, 분산과 같은 수치나 상관관계, 회귀선이
#모두 같다는 특징이 있다. 그래서 이런 결과를 보면 4개의
#데이터 그룹의 데이터는 모두 같을 것이라 착각할 수 있다.
#앤스콤 데이터 집합은 seaborn 라이브러리에 포함되어 있다.
#seaborn 라이브러리의 load_dataset()함수의 인수로 'anscombe'을
#전달하면 엔스콤 데이터 집합을 불러올 수 있다.
anscombe = sns.load_dataset('anscombe')
anscombe
| dataset | x | y | |
|---|---|---|---|
| 0 | I | 10.0 | 8.04 |
| 1 | I | 8.0 | 6.95 |
| 2 | I | 13.0 | 7.58 |
| 3 | I | 9.0 | 8.81 |
| 4 | I | 11.0 | 8.33 |
| 5 | I | 14.0 | 9.96 |
| 6 | I | 6.0 | 7.24 |
| 7 | I | 4.0 | 4.26 |
| 8 | I | 12.0 | 10.84 |
| 9 | I | 7.0 | 4.82 |
| 10 | I | 5.0 | 5.68 |
| 11 | II | 10.0 | 9.14 |
| 12 | II | 8.0 | 8.14 |
| 13 | II | 13.0 | 8.74 |
| 14 | II | 9.0 | 8.77 |
| 15 | II | 11.0 | 9.26 |
| 16 | II | 14.0 | 8.10 |
| 17 | II | 6.0 | 6.13 |
| 18 | II | 4.0 | 3.10 |
| 19 | II | 12.0 | 9.13 |
| 20 | II | 7.0 | 7.26 |
| 21 | II | 5.0 | 4.74 |
| 22 | III | 10.0 | 7.46 |
| 23 | III | 8.0 | 6.77 |
| 24 | III | 13.0 | 12.74 |
| 25 | III | 9.0 | 7.11 |
| 26 | III | 11.0 | 7.81 |
| 27 | III | 14.0 | 8.84 |
| 28 | III | 6.0 | 6.08 |
| 29 | III | 4.0 | 5.39 |
| 30 | III | 12.0 | 8.15 |
| 31 | III | 7.0 | 6.42 |
| 32 | III | 5.0 | 5.73 |
| 33 | IV | 8.0 | 6.58 |
| 34 | IV | 8.0 | 5.76 |
| 35 | IV | 8.0 | 7.71 |
| 36 | IV | 8.0 | 8.84 |
| 37 | IV | 8.0 | 8.47 |
| 38 | IV | 8.0 | 7.04 |
| 39 | IV | 8.0 | 5.25 |
| 40 | IV | 19.0 | 12.50 |
| 41 | IV | 8.0 | 5.56 |
| 42 | IV | 8.0 | 7.91 |
| 43 | IV | 8.0 | 6.89 |
print(anscombe[anscombe['dataset'] == 'I'].mean())
print('=' * 30)
print(anscombe[anscombe['dataset'] == 'II'].mean())
print('=' * 30)
print(anscombe[anscombe['dataset'] == 'III'].mean())
print('=' * 30)
print(anscombe[anscombe['dataset'] == 'IV'].mean())
x 9.000000
y 7.500909
dtype: float64
==============================
x 9.000000
y 7.500909
dtype: float64
==============================
x 9.0
y 7.5
dtype: float64
==============================
x 9.000000
y 7.500909
dtype: float64
dataset_1 = anscombe[anscombe['dataset'] == 'I']
dataset_2 = anscombe[anscombe['dataset'] == 'II']
dataset_3 = anscombe[anscombe['dataset'] == 'III']
dataset_4 = anscombe[anscombe['dataset'] == 'IV']
dataset x y
0 I 10.0 8.04
1 I 8.0 6.95
2 I 13.0 7.58
3 I 9.0 8.81
4 I 11.0 8.33
5 I 14.0 9.96
6 I 6.0 7.24
7 I 4.0 4.26
8 I 12.0 10.84
9 I 7.0 4.82
10 I 5.0 5.68
#plot() 함수로 그래프를 그린다. plot()함수의
#x,y축으로 데이터를 전달하면 그래프가 나타난다.
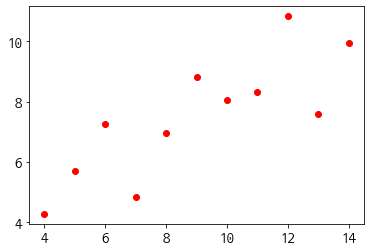
plt.plot(dataset_1['x'],dataset_1['y'], 'ro')
plt.show()
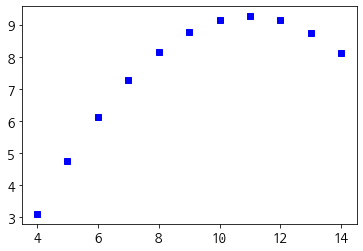
plt.plot(dataset_2['x'],dataset_2['y'], 'bs')
plt.show()
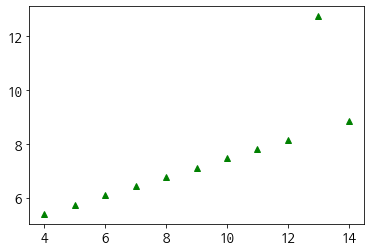
plt.plot(dataset_3['x'],dataset_3['y'], 'g^')
plt.show()
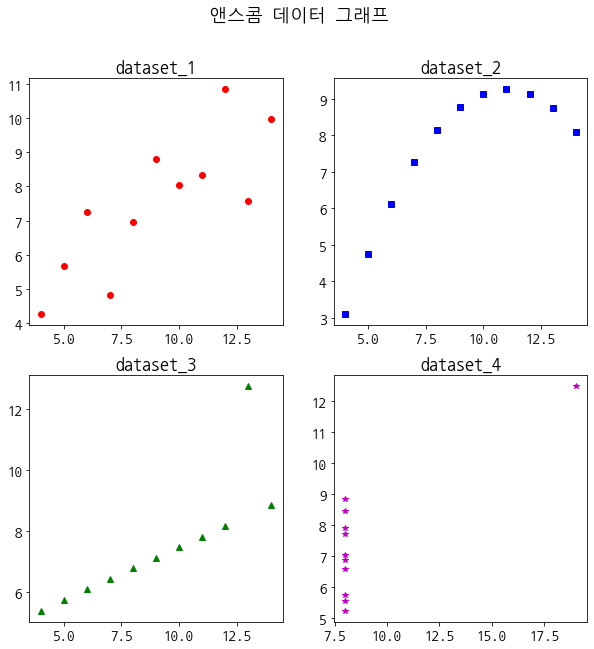
plt.plot(dataset_4['x'],dataset_4['y'], 'm*')
plt.show()

# figure() 함수로 전체 그래프가 그려질 기본 틀을 만든다.
fig = plt.figure()
plt.rcParams['figure.figsize'] = [10, 10]
#add_subplot()함수로 그래프가 그려질 격자를 만든다.
#=> add_subplot(행, 열, 위치)
axes1 = fig.add_subplot(2,2,1)
axes2 = fig.add_subplot(2,2,2)
axes3 = fig.add_subplot(2,2,3)
axes4 = fig.add_subplot(2,2,4)
#plot()함수로 격자에 데이터를 전달해 그래프를 그린다.
axes1.plot(dataset_1['x'],dataset_1['y'], 'ro')
axes2.plot(dataset_2['x'],dataset_2['y'], 'bs')
axes3.plot(dataset_3['x'],dataset_3['y'], 'g^')
axes4.plot(dataset_4['x'],dataset_4['y'], 'm*')
#set_title()함수로 각각의 그래프에 제목을 추가할 수 있다.
axes1.set_title('dataset_1')
axes2.set_title('dataset_2')
axes3.set_title('dataset_3')
axes4.set_title('dataset_4')
#suptitle()함수로 그래프 전체의 제목을 추가할 수 있다.
fig.suptitle('앤스콤 데이터 그래프')
plt.show()
댓글남기기