22_Data_Analysis_5
import warnings # 경고 메시지를 출력하고 싶지 않을 경우 import 한다.
warnings.filterwarnings('ignore') # 경고 메시지를 출력하지 않는다. 경고 메시지를 보고싶다면 default로 지정한다.
from IPython.display import Image # 쥬피터 노트북에 이미지를 출력하기 위해 import 한다.
import numpy as np # 배열 계산 라이브러리
import pandas as pd # 데이터 분석 라이브러리
import matplotlib.pyplot as plt # 시각화 라이브러리
plt.rcParams['font.family'] = 'NanumGothicCoding' # matplotlib의 글꼴 설정
plt.rcParams['font.size'] = 15 # matplotlib 글꼴 크기 설정
import matplotlib as mpl # matplotlib에서 음수 데이터의 '-' 기호가 깨지는 것을 방지하기 위해 import 한다.
mpl.rcParams['axes.unicode_minus'] = False # '-' 글꼴을 깨지지 않게한다.
import seaborn as sns # matplotlib를 기반으로 한 시각화 라이브러리
from plotnine import * # R의 ggplot2 패키지를 사용하는 것 처럼 사용하는 시각화 라이브러리
import missingno as msno # NaN 분포를 그래프 형태로 시각화 하는 라이브러리
import folium # 지도 시각화 라이브러리
서울시 공무원의 업무 추진비를 분석한 공무원 맛집 찾기
서울시는 업무 추진에 대한 비용 집행의 투명성을 제공하고자 공개된 시장단을 비롯해 4급 부서장 이상의 간부직 공무원의 업무 추진비 집행 내역을 공개합니다.
서울시 업무 추진비 url: https://opengov.seoul.go.kr/expense
# read_csv() 함수에 index_col 옵션을 사용하면 인덱스에 열 이름을 붙일 수 있다.
df = pd.read_csv('./data/raw.csv', index_col='연번')
df.shape

df.head()

df.tail()

df.dtypes

df.info()

msno.matrix(df, figsize=[14, 8])
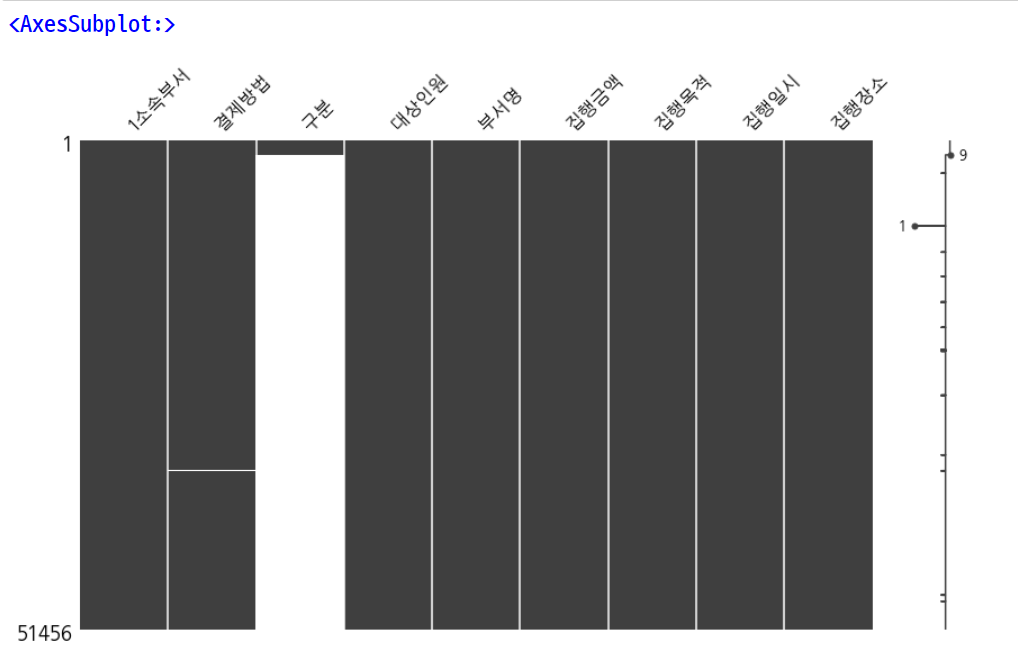
df.isnull().sum()

# 집행금액에 NaN인 데이터가 있다. 확인해보자
df[df['집행금액'].isnull()]

missing_df_row = df[df['집행금액'].isnull()].index[0]
missing_df_row

# 해당 행을 제거하고 다시 df 데이터프레임으로 저장한다.
print(df.shape)
df = df.drop(missing_df_row)
print(df.shape)

df.isnull().sum()

# 집행일시 열을 이용해서 '연', '월', '연월', '일', '시', '분', '요일' 파생 변수를 만든다.
# 판다스에서 to_datetime() 함수를 사용하면 문자열 형태의 날짜 데이터를 날짜/시간 형태의 데이터로 변환할 수 있다.
df['집행일시'] = pd.to_datetime(df['집행일시'])
df.dtypes

df['연'] = df['집행일시'].dt.year.astype(int)
df['월'] = df['집행일시'].dt.month.astype(int)
df['연월'] = df['연'].astype(str) + '-' + df['월'].astype(str)
df['일'] = df['집행일시'].dt.day.astype(int)
df['시'] = df['집행일시'].dt.hour.astype(int)
df['분'] = df['집행일시'].dt.minute.astype(int)
df['요일'] = df['집행일시'].dt.dayofweek.astype(int) # 0 => 월, 1 => 화, 2 => 수, 3 => 목, 4 => 금, 5 => 토, 6 => 일
df.head()

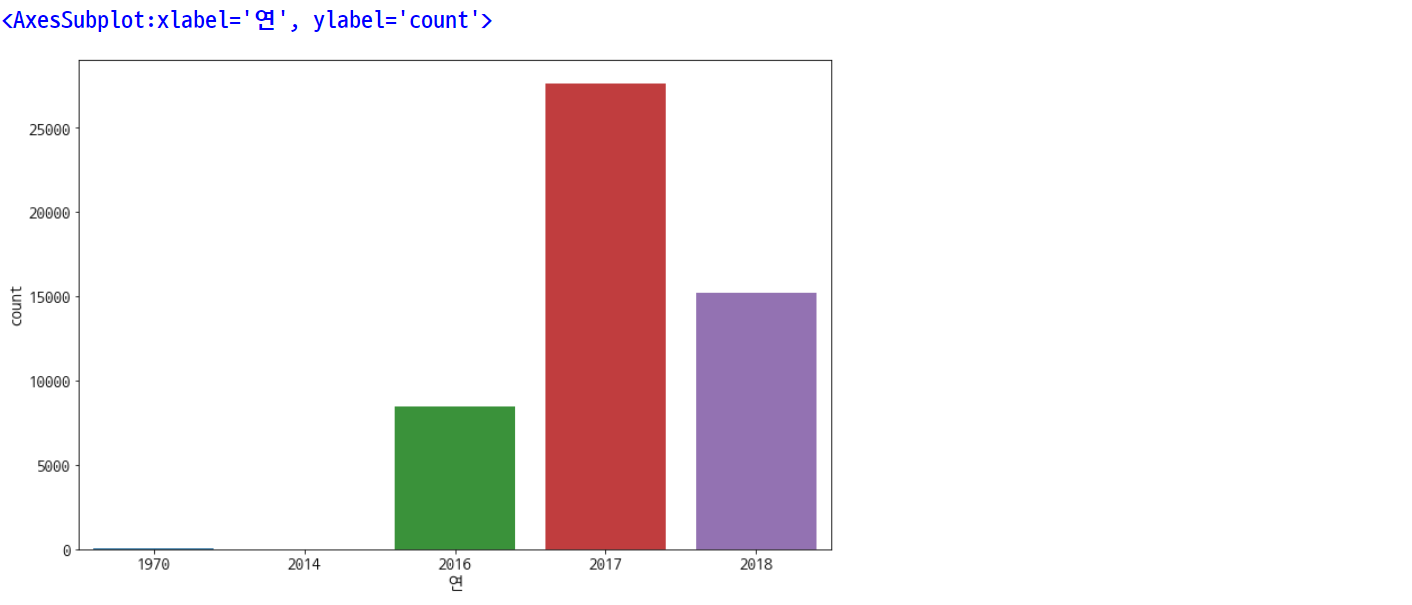
plt.rcParams['figure.figsize'] = [12, 8]
plt.rc('font', size=15)
sns.countplot(data=df, x='연')
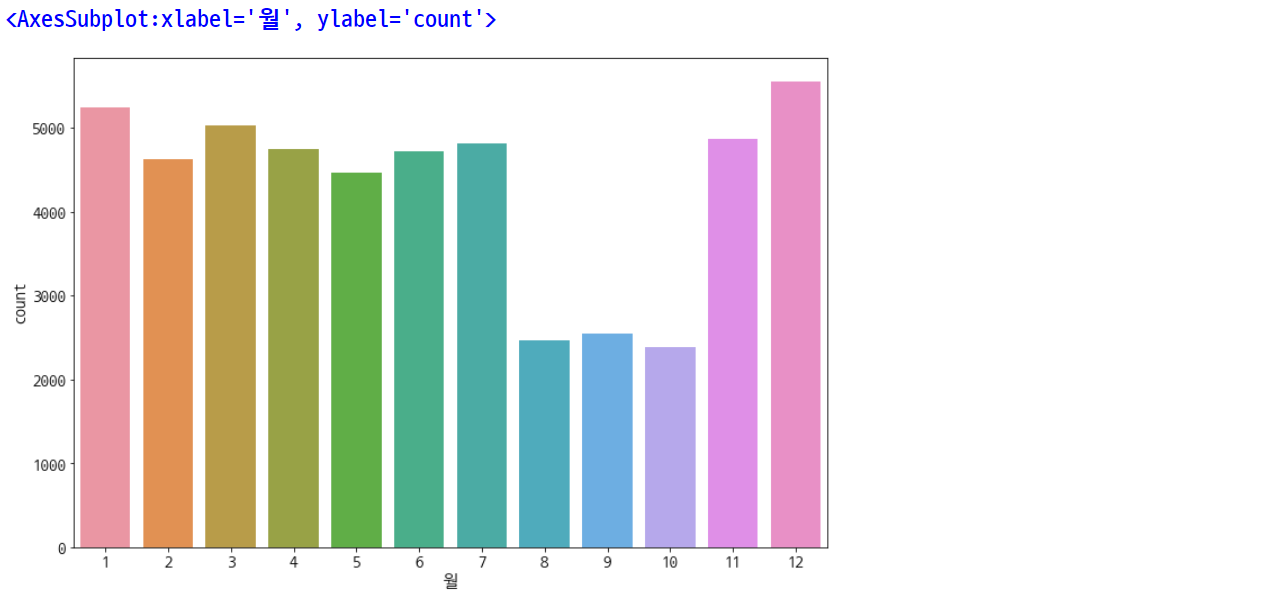
plt.rcParams['figure.figsize'] = [12, 8]
plt.rc('font', size=15)
sns.countplot(data=df, x='월')
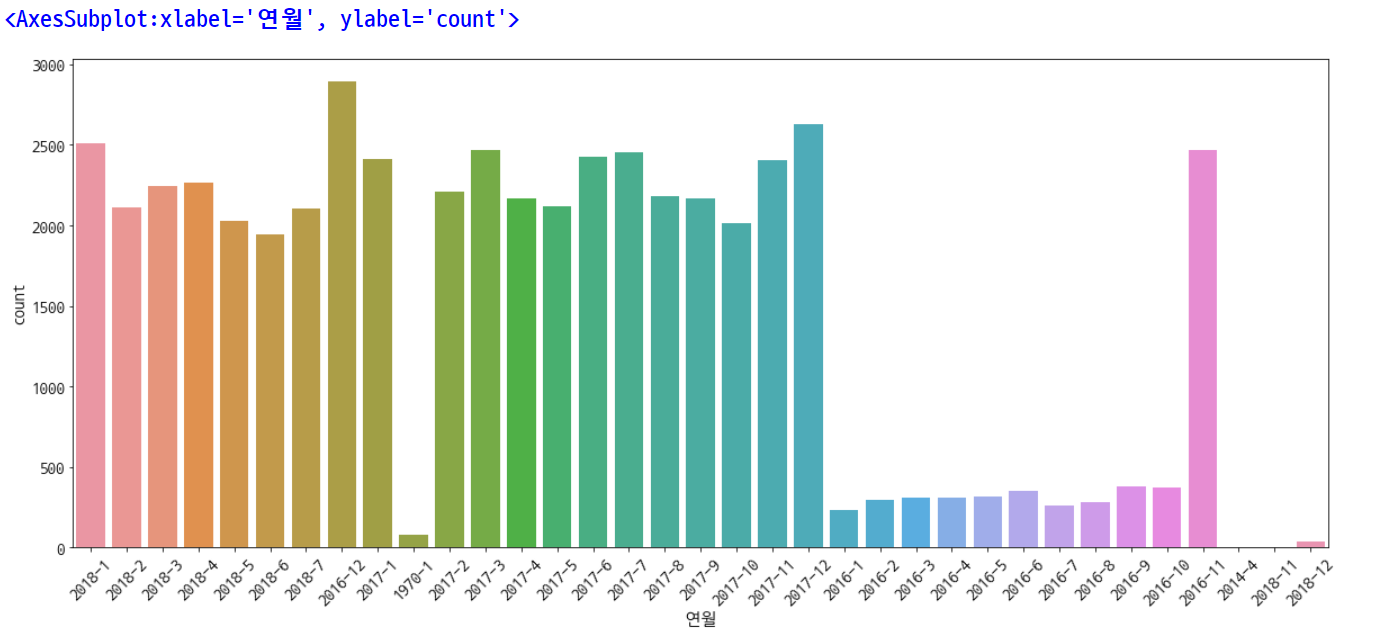
plt.rcParams['figure.figsize'] = [20, 8]
plt.rc('font', size=15)
plt.xticks(rotation=45)
sns.countplot(data=df, x='연월')
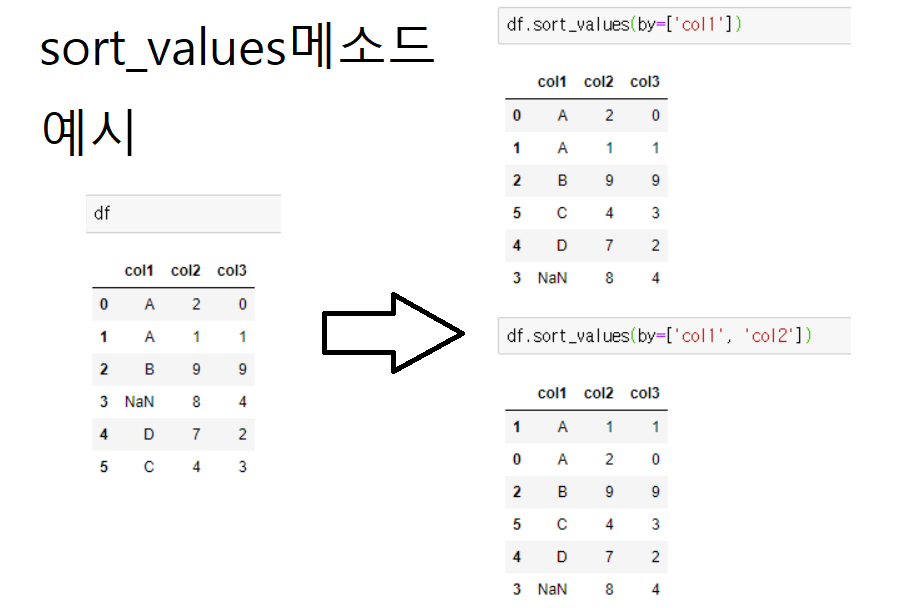
# 그래프에 '연월'순으로 보기 위해서 '연', '월'의 오름차순으로 정렬한다.
df = df.sort_values(by=['연', '월'], ascending=True)
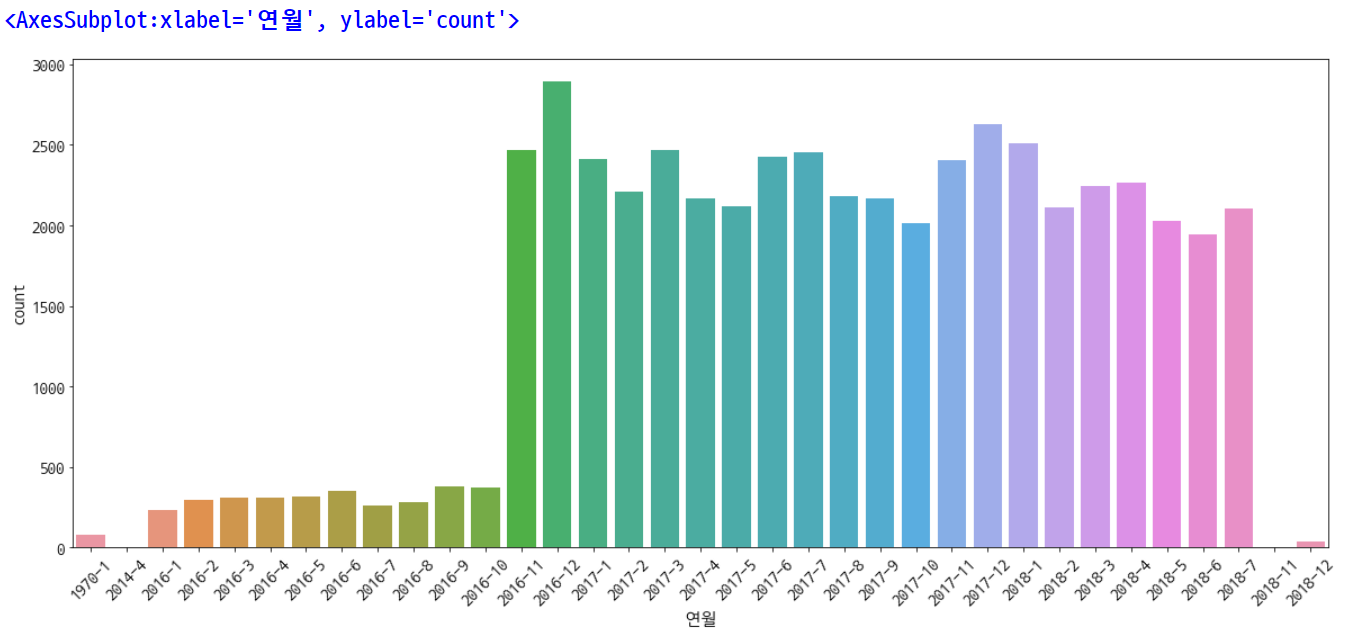
plt.rcParams['figure.figsize'] = [20, 8]
plt.rc('font', size=15)
plt.xticks(rotation=45)
sns.countplot(data=df, x='연월')
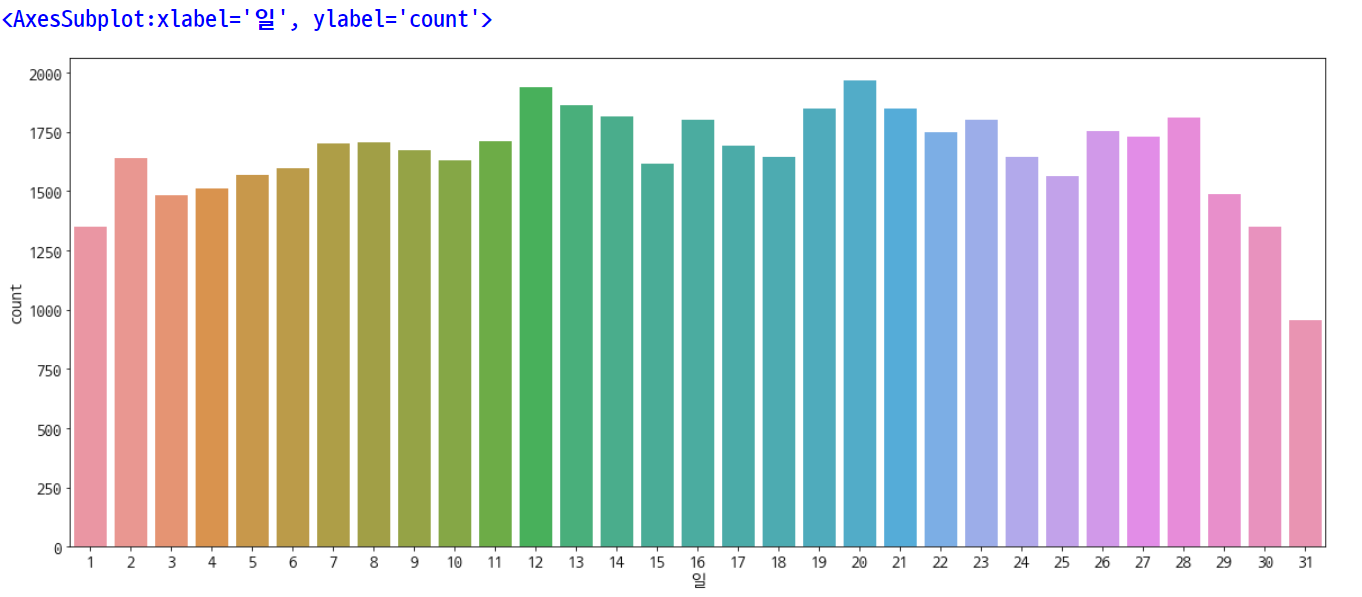
plt.rcParams['figure.figsize'] = [20, 8]
plt.rc('font', size=15)
sns.countplot(data=df, x='일')
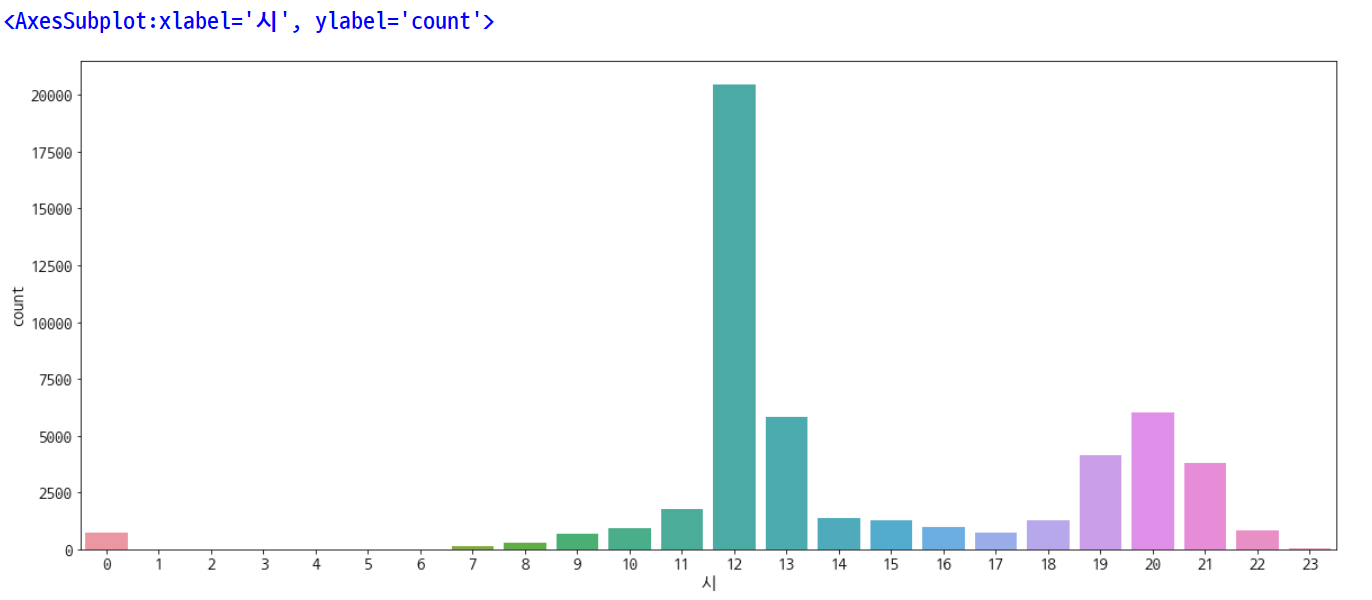
plt.rcParams['figure.figsize'] = [20, 8]
plt.rc('font', size=15)
sns.countplot(data=df, x='시')
plt.rcParams['figure.figsize'] = [12, 8]
plt.rc('font', size=15)
sns.countplot(data=df, x='요일')
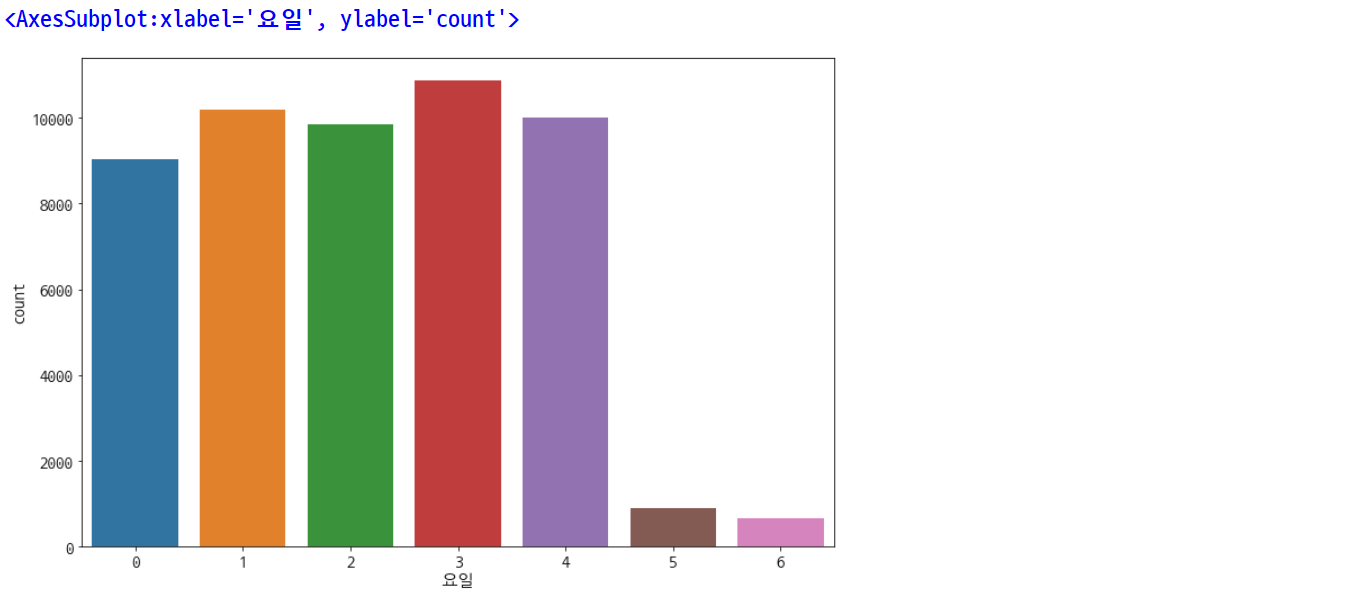
# 0 => 월, 1 => 화, 2 => 수, 3 => 목, 4 => 금, 5 => 토, 6 => 일
weekday = {0: '월', 1: '화', 2: '수', 3: '목', 4: '금', 5: '토', 6: '일'}
df['요일_한글'] = df['요일'].apply(lambda x: weekday[x])
df.head()

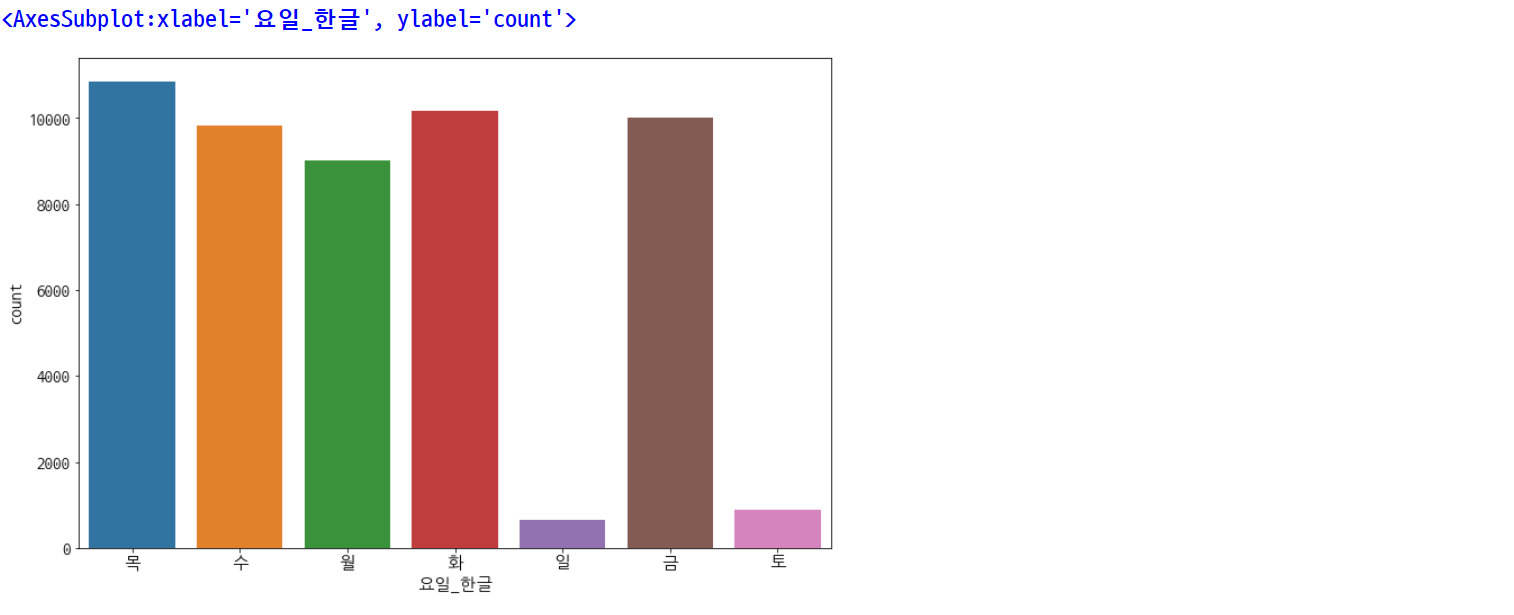
plt.rcParams['figure.figsize'] = [12, 8]
plt.rc('font', size=15)
sns.countplot(data=df, x='요일_한글')
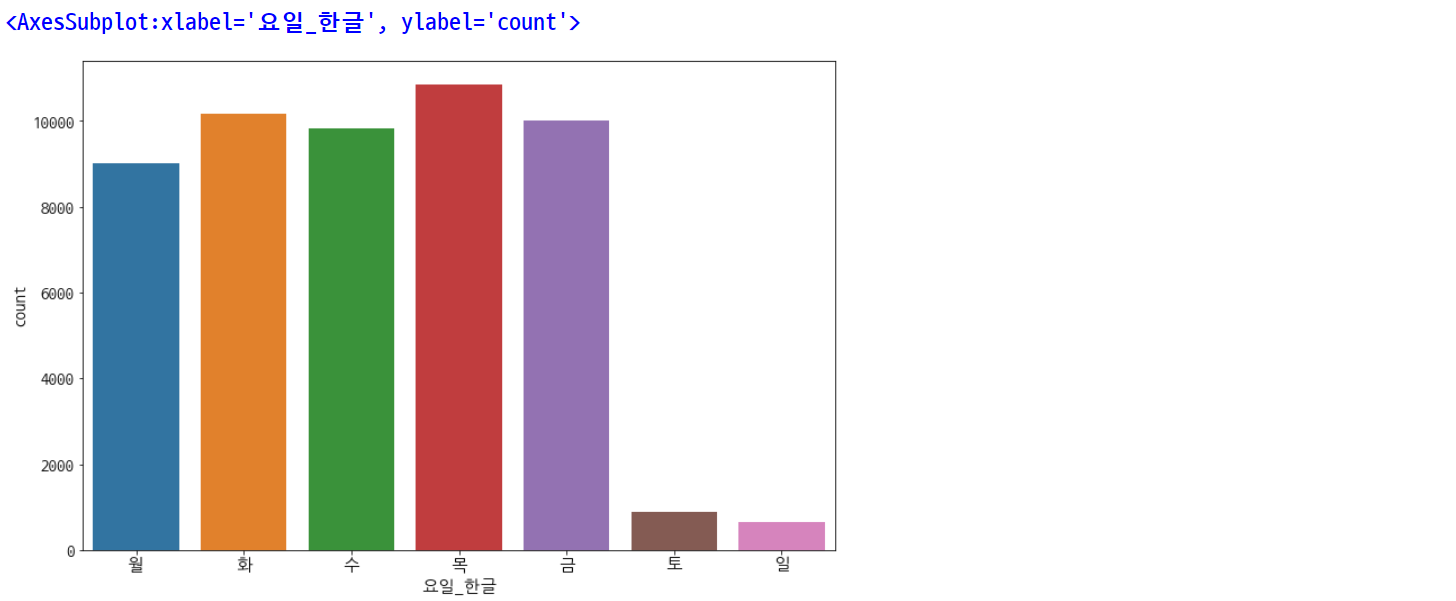
plt.rcParams['figure.figsize'] = [12, 8]
plt.rc('font', size=15)
sns.countplot(data=df.sort_values(by=['요일']), x='요일_한글')
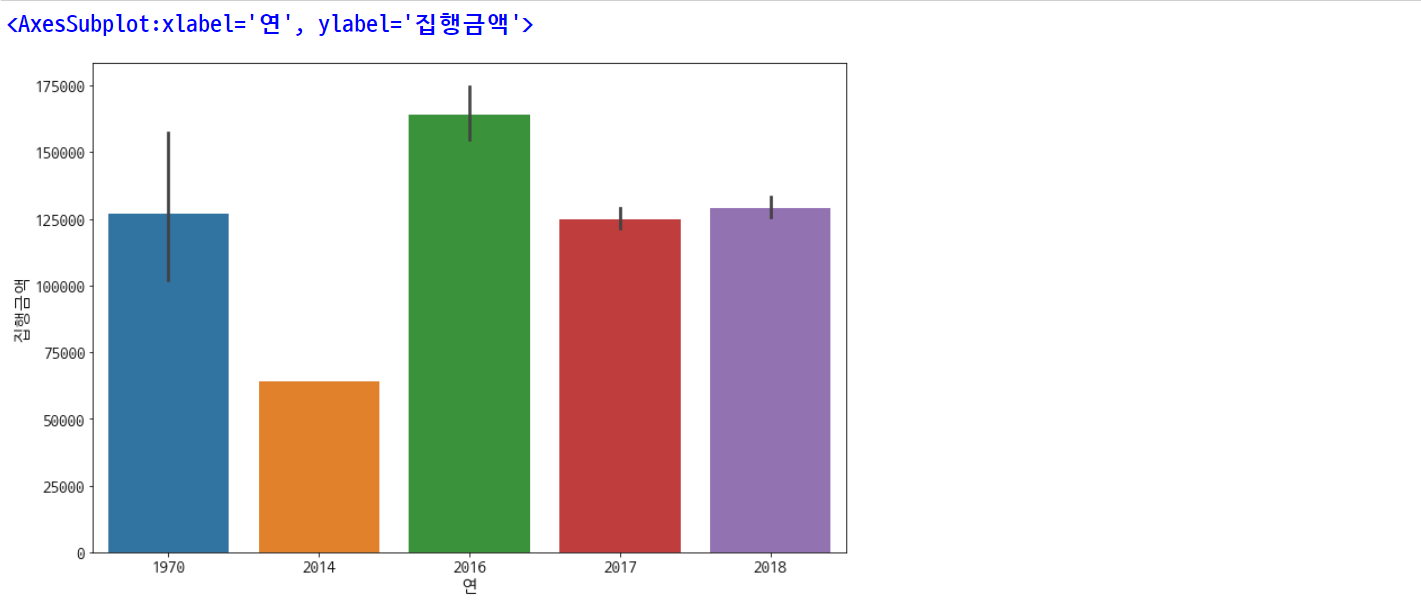
plt.rcParams['figure.figsize'] = [12, 8]
plt.rc('font', size=15)
sns.barplot(data=df, x='연', y='집행금액')
plt.rcParams['figure.figsize'] = [12, 8]
plt.rc('font', size=15)
sns.barplot(data=df, x='월', y='집행금액')
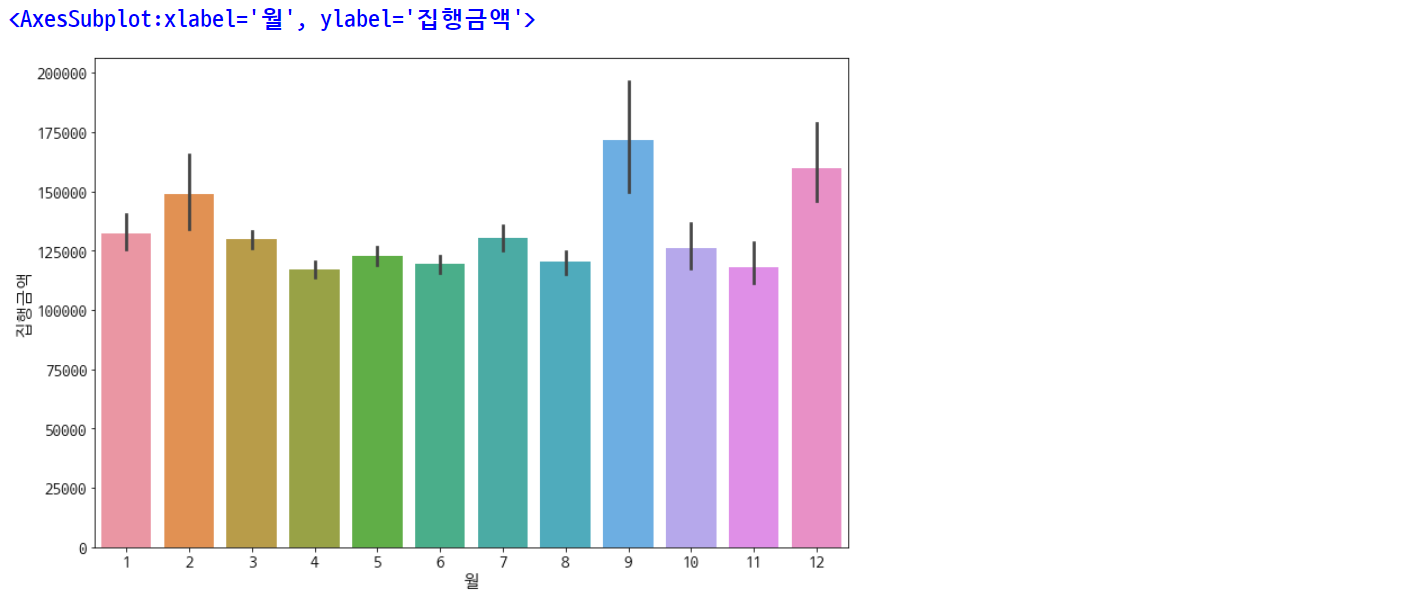
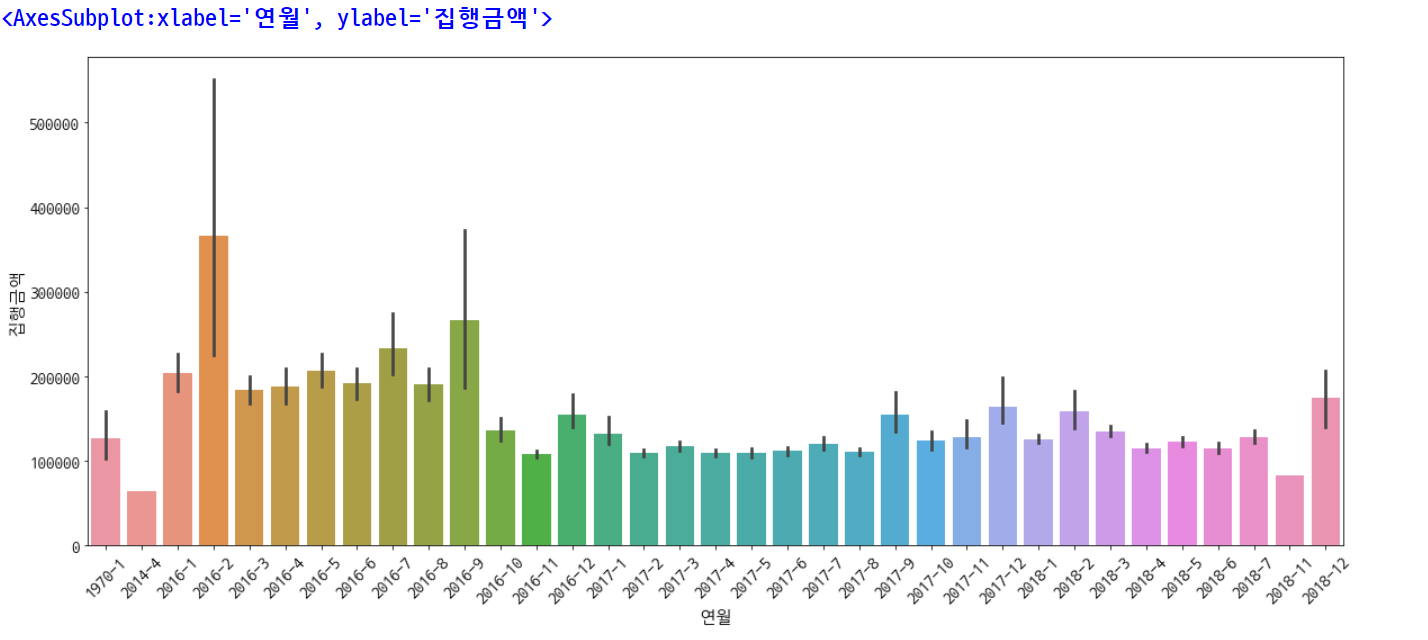
plt.rcParams['figure.figsize'] = [20, 8]
plt.rc('font', size=15)
plt.xticks(rotation=45)
sns.barplot(data=df, x='연월', y='집행금액')
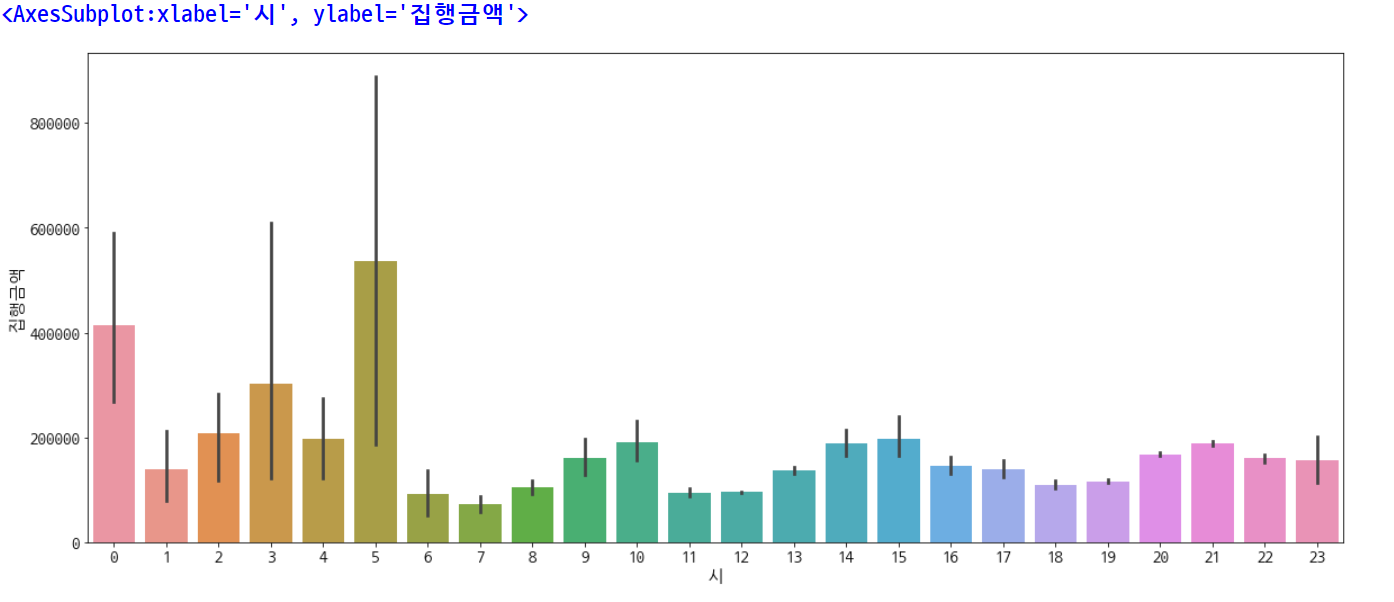
plt.rcParams['figure.figsize'] = [20, 8]
plt.rc('font', size=15)
sns.barplot(data=df, x='시', y='집행금액')
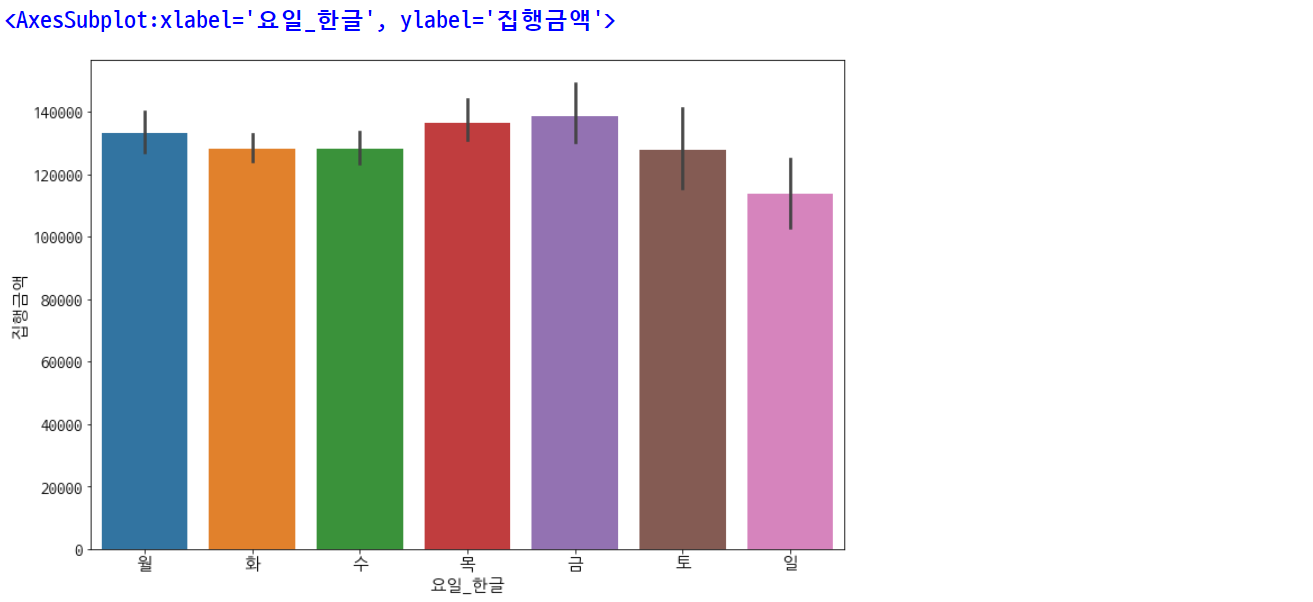
plt.rcParams['figure.figsize'] = [12, 8]
plt.rc('font', size=15)
sns.barplot(data=df.sort_values(by='요일'), x='요일_한글', y='집행금액')
집행목적 워드클라우드
from wordcloud import WordCloud
df.head()

#집행목적이 NaN인 데이터를 확인한다.
df[df['집행목적'].isnull()]
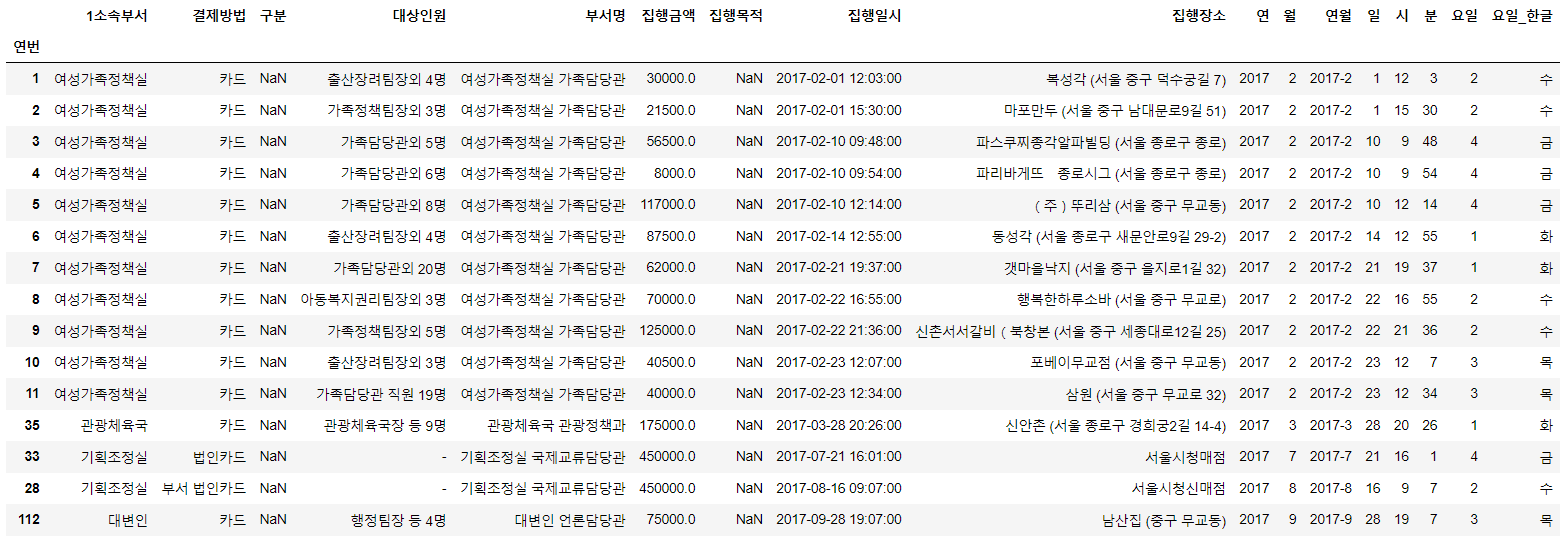
#집행목적이 NaN인 데이터가 존재하므로 NaN을 공백으로 채워준다.
df['집행목적'] = df['집행목적'].fillna('')
df[df['집행목적'].isnull()]

#파이썬 문자열 함수 등 특정 문자열을 문자열 사이에
#삽입하는 join()함수로 집행목적을 연결해 워드클라우드를
#실행한다.
spend_gubun = ' '.join(df['집행목적'])
spend_gubun

wordcloud = WordCloud(
font_path='C:\\Users\\user\\AppData\\Local\\Microsoft\\Windows\\Fonts\\NanumGothicCoding.ttf',
background_color ='black',
relative_scaling =0.5
).generate(spend_gubun)
plt.figure(figsize=[16,12])
plt.imshow(wordcloud)
plt.axis('off')
plt.show()

집행장소 워드클라우드
# 집행장소가 NaN인 데이터를 확인한다.
df[df['집행장소'].isnull()]
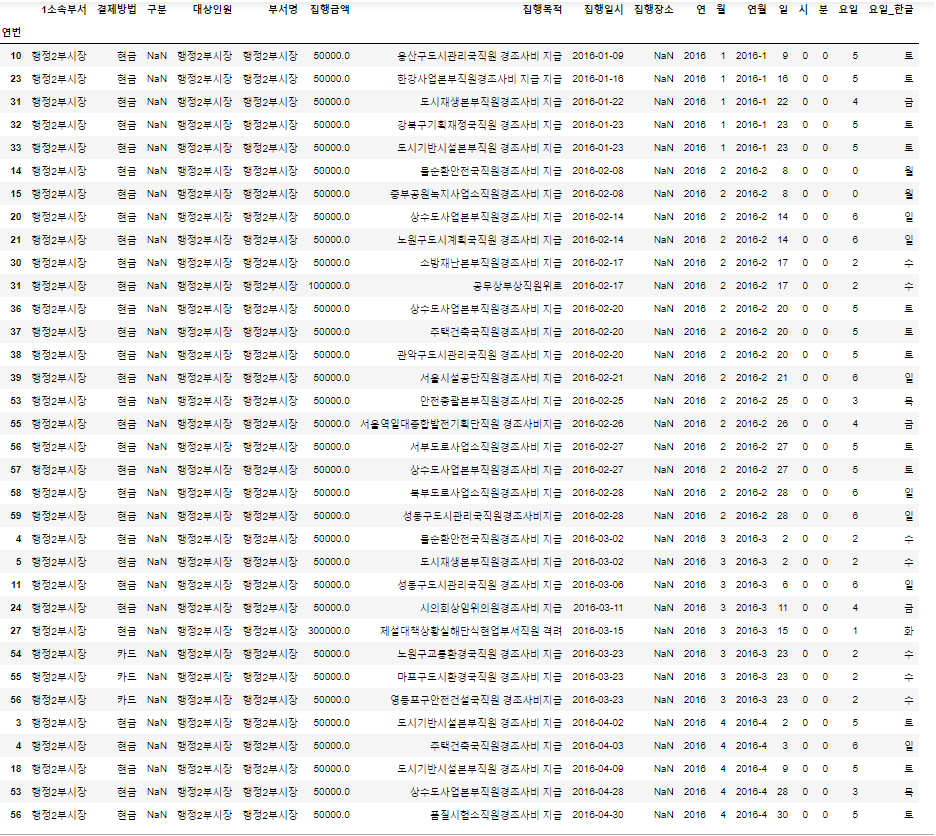
# 집행장소가 NaN인 데이터가 존재하므로, NaN을 공백으로 채워준다.
df['집행장소'] = df['집행장소'].fillna('')
df[df['집행장소'].isnull()]

df.head()

'뼈큰감자탕 (대구 중구 명덕로)'.split('(')[0].strip()

#집행장소에 주소가 많이 보이기 때문에 주소는 전처리를 통해
#제거하고 '상호명'이라는 파생 변수를 만들어 집행장소에서
#상호명을 가져온다.
#상호명이 여는 괄호 앞쪽에 있으므로 여는 괄호 앞에 있는 것을
#상호명으로 한다.
df['상호명'] = df['집행장소'].apply(lambda x: x.split('(')[0].strip())
df.head()

#상호명이 공백인 데이터의 집행목적을 확인한다.
df.loc[df['상호명'] == '', '집행목적'].value_counts().head()

#상호명이 '대상자 소속부서'인 데이터의 집행목적을 확인한다.
#상호명이 공백인 데이터의 집행목적을 확인한다.
df.loc[df['상호명'] == '대상자 소속부서', '집행목적'].value_counts().head()

# 상호명이 '-'인 데이터의 집행목적을 확인한다.
df.loc[df['상호명'] == '-', '집행목적'].value_counts().head()

#상호명이 공백, '대상자 소속부서', '-'인 데이터(잘못된 데이터)를
#제거한다.
df_shop=df[(df['상호명'] !='')
& (df['상호명'] !='대상자 소속부서')
& (df['상호명'] !='-')
]
df_shop
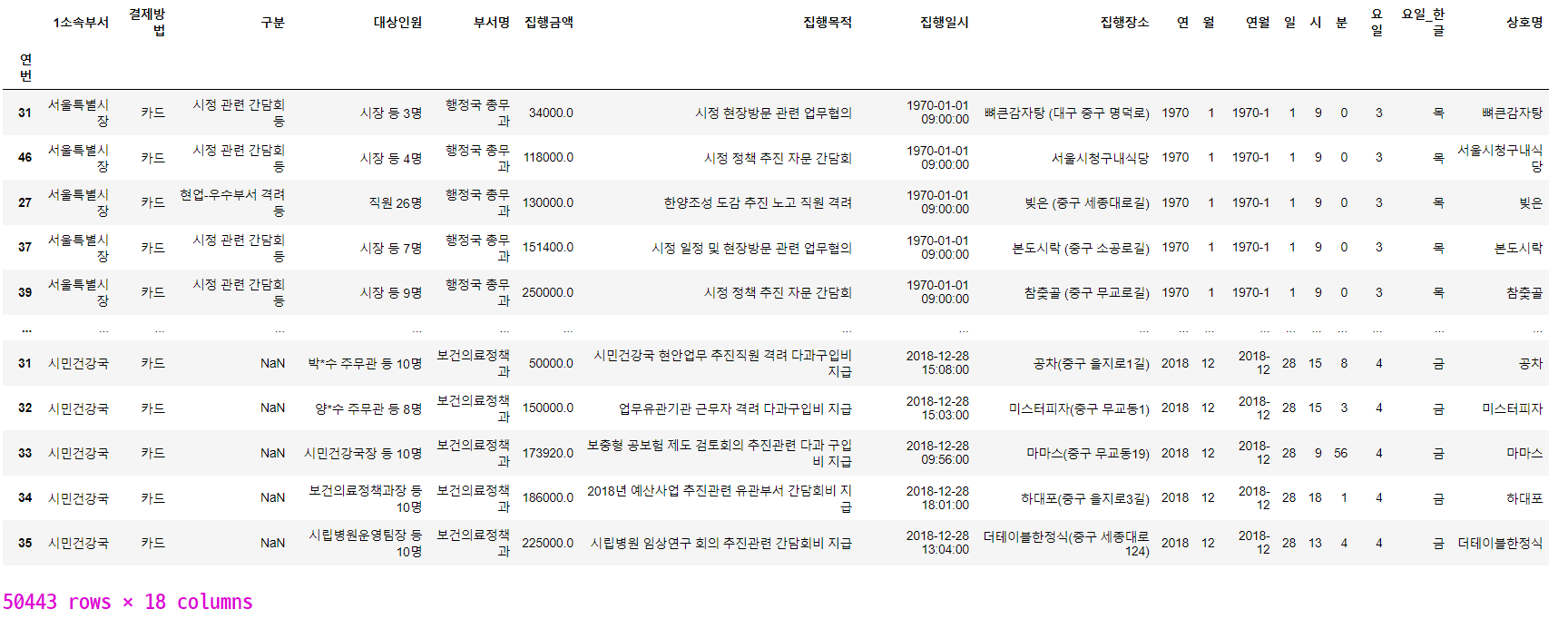
df_shop['상호명'].value_counts().head(30)

df_shop.loc[df_shop['상호명'] == '(주)바닷가작은부엌', '상호명'] = '바닷가작은부엌'
df_shop['상호명'].value_counts().head(30)

top_100 = df_shop['상호명'].value_counts().head(100)
top_100 = pd.DataFrame(top_100).reset_index()
top_100.columns=['상호명', '방문횟수']
top_100

wordcloud = WordCloud(
font_path='C:\\Users\\user\\AppData\\Local\\Microsoft\\Windows\\Fonts\\NanumGothicCoding.ttf',
background_color ='black',
relative_scaling =0.5
).generate(' '.join(top_100['상호명']))
plt.figure(figsize=[16,12])
plt.imshow(wordcloud)
plt.axis('off')
plt.show()

top_100[top_100['상호명'] =='뚜리삼']

댓글남기기