27_Linear_Regression_선형회귀
import warnings
warnings.filterwarnings('ignore')
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
WARNING:tensorflow:From c:\python\lib\site-packages\tensorflow\python\compat\v2_compat.py:101: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term
학습 데이터를 만든다.
xData = [1,2,3,4,5,6,7] #근무 시간
#근무시간에 따른 매출금액 => 실제 관찰된 값 => 실제값
yData = [2500, 5500, 7500, 11000, 128000, 155000, 180000]
난수를 발생시켜 학습할 데이터의 기울기(가중치)와 y절편(바이어스)를 정한다.
난수를 발생시켜 작업하는 이유는 과적합을 방지하기 위해서이다.
과적합이란 학습에 사용한 데이터에서는 높은 정확도를 보이지만 학습시킨
데이터 이외의 데이터에서는 낮은 정확도를 보이는 문제를 말한다.
#random_uniform([난수의 개수], 난수의 최소값, 난수의 최대값) 함수로
#균등분포로부터 난수값을 발생시킨다.
#기울기(가중치), -100~100사이 난수
a = tf.Variable(tf.random_uniform([1], -100, 100))
#y절편(바이어스), -100~100사이 난수
b = tf.Variable(tf.random_uniform([1], -100, 100))
print('a : {}, b : {}'.format(a,b))
a : <tf.Variable 'Variable:0' shape=(1,) dtype=float32_ref>, b : <tf.Variable 'Variable_1:0' shape=(1,) dtype=float32_ref>
sess = tf.Session()
sess.run(tf.global_variables_initializer())
print('a : {}, b : {}'.format(sess.run(a),sess.run(b)))
a : [-32.87706], b : [-50.900627]
근무 시간과 매출 금액을 기억할 placeholder를 선언한다.
x = tf.placeholder(dtype=tf.float32) # 근무 시간(xData)를 기억하는 placeholder
y = tf.placeholder(dtype=tf.float32) # 매출 금액(yData)를 기억하는 placeholder
1차 방정식 형태의 가설을 세우고 오차(비용) 함수를 정의한다.
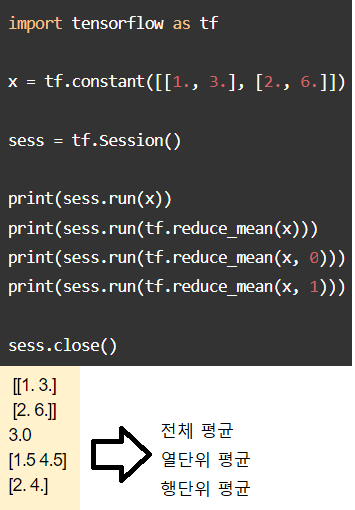
#1차 방정식 형태의 가설 Y(에측값)를 정의한다.
Y = a * x + b
#비용(오차) 함수 => 실제값(yData => y라는 placeholder에 저장한다.)과
# 예측값(Y)의 편차의 제곱에 대한 평균을 이용한다.
# (평균 제곱법)
#reduce_mean() 함수로 차원을 제거하고 tensorflow에서 평균을 계산한다.
#square() 함수로 tensorflow에서 제곱갓을 계산한다.
#sqrt()함수로 tensorflow에서 제곱근 값을 게산한다.
#예측값과 실제값의 편차에 대한 평균을 계산한다.
cost = tf.reduce_mean(tf.square(Y - y))
경사 하강법을 이용해서 비용(오차) 함수의 결과를 가장 작게 만드는 방향으로 학습시키도록 정의한다.
# 경사 하강 알고림즘의 학습율을 설정한다.
learning_rate = 0.2
#train.GradientDescentOptimizer(학습율) 함수로 학습율에 따른 바용(요차)
#함수를 게산한다.
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
#minimize() 함수로 경사 하강 알고리즘에 따라 인수로 지정된 비용(오차)
#함수의 최소값을 찾는다.
#train = optimizer.minimize(cost)
train = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
학습시킨다.
#세션을 만들고 변수를 초기화시킨다.
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(100001):
# 비용(오차) 함수를 가장 작게 만드는 학습을 할 수 있도록
# placeholder에 데이터를 대입한다.
# 학습할 데이터는 반드시 'feed_dict'라는 이름의 딕셔너리 타입의
# 자료형을 만들어 대입해야 한다.
# 'feed_dict' 딕셔너리의 key에는 placeholder의 이름을, value에는
# 각 placeholder에 대입할 리스트 타입의 데이터를 지정한다.
# tensorflow 세션에서 비용(오차) 함수를 가장 작게 만드는 방향으로
# 'feed_dict'딕셔너리의 데이터로 학습시킨다.
sess.run(train, feed_dict={x: xData, y: yData})
# 500 Epoch 단위로 학습이 될 때 마다 머신러닝이 실행되는
# 중간 결과를 확인한다.
if i % 5000==0:
# i,오차,기울기,y절편
#print(i, sess.run(cost, feed_dict={x: xData, y: yData}), sess.run(a), sess.run(b))
print('{0:5d}. {1:10.3f} {2:8.3f} {3:8.3f}'.format(i, sess.run(cost, feed_dict={x: xData, y: yData}), sess.run(a)[0], sess.run(b)[0]))
0. 87309656064.000 83210.203 14044.899
5000. nan nan nan
10000. nan nan nan
15000. nan nan nan
20000. nan nan nan
25000. nan nan nan
30000. nan nan nan
35000. nan nan nan
40000. nan nan nan
45000. nan nan nan
50000. nan nan nan
55000. nan nan nan
60000. nan nan nan
65000. nan nan nan
70000. nan nan nan
75000. nan nan nan
80000. nan nan nan
85000. nan nan nan
90000. nan nan nan
95000. nan nan nan
100000. nan nan nan
print('a : {}, b : {}'.format(sess.run(a),sess.run(b)))
a : [nan], b : [nan]
import time
for i in range(9, 25):
print('{0:2d}시간 근무했을 때 매출 기대금액 : {1:7,.0f}'.format(i,sess.run(Y,feed_dict={x : [i]})[0]))
time.sleep(0.5)
9시간 근무했을 때 매출 기대금액 : nan
10시간 근무했을 때 매출 기대금액 : nan
11시간 근무했을 때 매출 기대금액 : nan
12시간 근무했을 때 매출 기대금액 : nan
13시간 근무했을 때 매출 기대금액 : nan
14시간 근무했을 때 매출 기대금액 : nan
15시간 근무했을 때 매출 기대금액 : nan
16시간 근무했을 때 매출 기대금액 : nan
17시간 근무했을 때 매출 기대금액 : nan
18시간 근무했을 때 매출 기대금액 : nan
19시간 근무했을 때 매출 기대금액 : nan
20시간 근무했을 때 매출 기대금액 : nan
21시간 근무했을 때 매출 기대금액 : nan
22시간 근무했을 때 매출 기대금액 : nan
23시간 근무했을 때 매출 기대금액 : nan
24시간 근무했을 때 매출 기대금액 : nan
댓글남기기