30_Gradient_Descent_경사하강법
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
WARNING:tensorflow:From c:\python\lib\site-packages\tensorflow\python\compat\v2_compat.py:101: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term
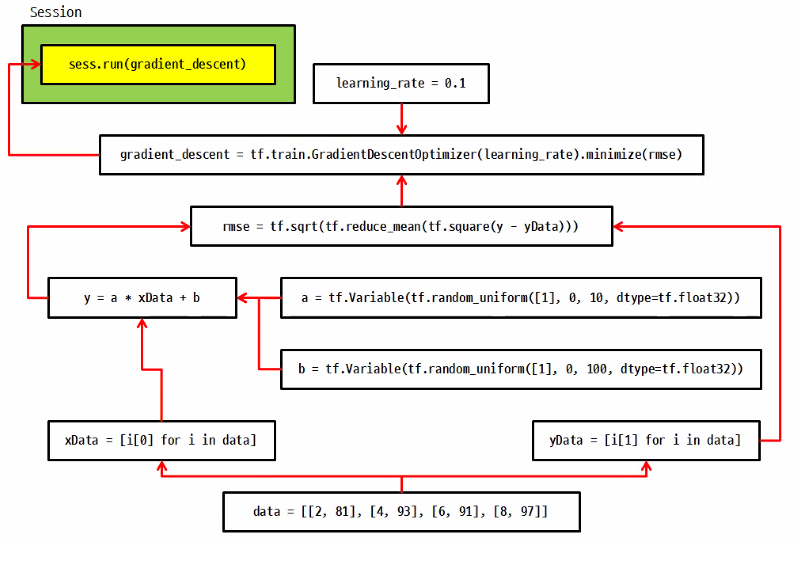
data = [[2,81],[4,93],[6,91],[8,97]] #[공부한 시간(x), 실제 성적(y)]
xData=[i[0] for i in data] #공부한 시간
yData=[i[1] for i in data] #시험 성적(실제성적)
#기울기 a와 y절편 b를 임의로 정한다.
#기울기의 범위는 0~10사이이며, y절편의 범위는
#0~100사이에서 임의로 변하게 한다.
#random_uniform()함수는 tensorflow에서 균등 분포의 난수를 발생시킨다.
#tf.random_uniform([난수의 개수], 난수의 최소값, 난수의 최대값, dtype=난수의 데이터 타입, seed=숫자)
#난수 발생시 seed를 지정하면 항상 일정한 배열의 난수가 발생된다.
a=tf.Variable(tf.random_uniform([1],0,10,dtype=tf.float32))
b=tf.Variable(tf.random_uniform([1],0,100,dtype=tf.float32))
sess = tf.Session()
sess.run(tf.global_variables_initializer())
print('a={}, b={}'.format(sess.run(a), sess.run(b)))
a=[5.16829], b=[42.651283]
#예측 성적(y)을 얻기위한 가설(수식)을 만든다.
y = a*xData + b
#RMSE(평균 제곱근 오차) 수식(오차(비용)함수)을 만든다.
#예측 성적과 실제 성적의 편차의 제곱에 대한 평균의 제곱근을
#계산한다.
rmse = tf.sqrt(tf.reduce_mean(tf.square(y-yData)))
#경사 하강법 알고리즘을 이용해서 RMSE를 최소로 하는 값을 찾는
#수식을 만든다.
#학습율을 정한다.
learning_rate = 0.1
#GradientDescentOptimizer(학습율)함수로 학습율에 따른 경사 하강
#알고리즘을 계산한다.
gradient_descent = tf.train.GradientDescentOptimizer(learning_rate).minimize(rmse)
학습시킨다.
import time
from IPython.display import Image
Image('./structure.png', width ='800')
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(3001):
#gradient_descent에 연산결과가 아닌 수식이 들어가 있다.
sess.run(gradient_descent)
if i % 200 ==0:
#Epoch => 한번 학습을 의미하는 용어,
# RMSE, 기울기(2.3에 가까워진다.)
# y절편(79에 가까워진다.)
#print('Epoch : %4d, RMSE : %7.4f, 기울기 : %7.4f, y절편 : %7.4f'
# %(i, sess.run(rmse), sess.run(a), sess.run(b)))
#넘파이 배열(아래 예시의 경우'[]'안에 데이터가 하나 들어있다)에서
#서식을 지정해서 꺼내려면 [0]붙여줘야 한다.
print('Epoch : {0:4d}, RMSE : {1:7.4f}, 기울기 : {2:7.4f}, y절편 : {3:7.4f}'
.format(i, sess.run(rmse), sess.run(a)[0], sess.run(b)[0]))
time.sleep(0.25)
Epoch : 0, RMSE : 50.0154, 기울기 : 6.9512, y절편 : 6.9067
Epoch : 200, RMSE : 25.9401, 기울기 : 12.8809, y절편 : 15.8578
Epoch : 400, RMSE : 22.7429, 기울기 : 11.5593, y절편 : 23.7443
Epoch : 600, RMSE : 19.5607, 기울기 : 10.2408, y절편 : 31.6124
Epoch : 800, RMSE : 16.4018, 기울기 : 8.9272, y절편 : 39.4516
Epoch : 1000, RMSE : 13.2826, 기울기 : 7.6219, y절편 : 47.2414
Epoch : 1200, RMSE : 10.2379, 기울기 : 6.3322, y절편 : 54.9376
Epoch : 1400, RMSE : 7.3539, 기울기 : 5.0771, y절편 : 62.4276
Epoch : 1600, RMSE : 4.8746, 기울기 : 3.9139, y절편 : 69.3690
Epoch : 1800, RMSE : 3.3625, 기울기 : 3.0116, y절편 : 74.7533
Epoch : 2000, RMSE : 2.9439, 기울기 : 2.5485, y절편 : 77.5173
Epoch : 2200, RMSE : 2.8877, 기울기 : 2.3812, y절편 : 78.5157
Epoch : 2400, RMSE : 2.8817, 기울기 : 2.3263, y절편 : 78.8432
Epoch : 2600, RMSE : 2.8810, 기울기 : 2.3085, y절편 : 78.9493
Epoch : 2800, RMSE : 2.8810, 기울기 : 2.3028, y절편 : 78.9836
Epoch : 3000, RMSE : 2.8810, 기울기 : 2.3009, y절편 : 78.9947
댓글남기기