43_Ensenble_Random_Forest
앙상블(ensemble)
여러 개의 분류 모델을 조합해서 더 나은 성능을 내는 방법이다. 최근접 이웃, 서포트 벡터 머신, 의사결정 트리, 나이브 베이즈 분류 모델을 실습했는데 지금까지 실습한 여러 분류 모델을 조합해서 단일 모델모다 더 좋은 성능을 낸다.
배깅(bagging)
부트스트랩(bootstrap)과 어그리게이팅(aggregating, 집계)에서 왔고 상당히 연주하기 힘든 바이올린 연주곡을 두세 명의 초급 바이올린 연주자가 나누어 연주함으로써 한 명의 중급 바이올린 연주자가 연주하는 것 보다 더 나은 연주를 할 수 있는 것과 유사하다.중급 바이올린 연주자는 나름 잘 학습했지만 학습 데이터에 과대적합된 의사결정 트리라 볼 수 있다. 의사결정 트리의 단점은 쉽게 과적합된다는 것인데 배깅은 과대적합이 쉬운 모델에 상당히 적합한 앙상블이다.
랜덤 포레스트(random forest)
여러 의사결정 트리를 배깅을 적용해서 예측을 실행하는 모델이다.
배깅이 모든 분류 모델에서 적용 가능하지만 특히 과대적합되기 쉬운 의사결정 트리에 적용하면 확실히 과대적합을 줄여 성능이 높아지는 혜택을 보기 때문에 배깅은 많은 의사결정 트리 모델의 개선을 이뤘고 여러 개의 나무들이 모여있다는 개념에서 랜덤 포레스트라는 이름이 생겨났다.
의사결정 트리에서는 최적의 특징으로 트리를 분기하는 반면 랜덤 포레스트는 각 노드에 주어진 데이터를 샘플링해서 일부 데이터를 제외한 채 최적의 특징을 찾아 트리를 분기한다. 이러한 과정에서 랜덤 포레스트는 또 한 번 모델의 편향을 증가시켜 과대적합의 위험을 감소시킨다.
부스팅(Boosting)
여러 개의 분류기를 만들어 투표를 통해 예측값을 결정한다는 측면에서는 배깅과 동일하다.
배깅은 서로 다른 알고리즘에 기반한 여러 분류기를 병렬적으로 학습하는 반면에 부스팅은 동일한 알고리즘의 분류기를 순차적으로 학습해서 여러 개의 분류기를 만든 후 테스트할 때 가중 투표를 통해 예측값을 결정한다.
from IPython.display import Image
Image('./data/bootstrap.png', width=900)

MNSIT 손글씨 데이터셋으로 랜덤 포레스트 모델과
의사 결정 트리 모델을 동일하게 학습시켜 두 모델의
성능 차이를 시각화해 비교한다.
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import sklearn
#MNIST 손글씨 데이터셋을 사용하기 위해 import 시킨다.
from sklearn import datasets
#의사결정 트리오와 랜덤 포레스트 분류기를 import시킨다.
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
#교차 검증을 위해서 import 시킨다.
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt

MINST 손글씨 데이터 불러오기
mnist = datasets.load_digits()
features, labels = mnist.data, mnist.target
교차 검증
사이킷런의 cross_val_score() 함수는 데이터를 k개로 나눠서
k번 정확도를 검증하는 k-fold 교차 검증을 수행한다.
cross_val_score(model, X, Y, scoring=None, cv=None)
model : 회귀 분석 모델
X : 독릭 변수 데이터(학습 데이터)
Y : 종속 변수 데이터(학습 결과)
학습에 따른 결과는 1차원 형태로 지정해야 한다.
scoring=None : 성능 검증에 사용할 매개 변수에 원하는
평가 지표를 지정한다.
=>정확도를 의미하는 ‘accuracy’를 입력한다.
cv=None : 교차 검증 생성기 객체 또는 숫자, None일 경우
KFold(3), 숫자를 지정하면 KFold(숫자)
#MINST 데이터에 의한 의사결정 트리와 랜덤
#포레스트의 검증 정확도를 계산하는 함수를
#만든다.
def cross_validation(classifier, features, labels):
cv_scores = []
for i in range(10):
scores = cross_val_score(classifier, features, labels, cv=10, scoring='accuracy')
print(scores)
cv_scores.append(scores.mean())
return cv_scores
#의사결정 트리의 MNIST 손글씨 검증 정확도를 계산한다.
dt_cv_scores = cross_validation(tree.DecisionTreeClassifier(), features, labels)
for i in range(len(dt_cv_scores)):
print('{0:2d} : {1:7.5f}'.format(i+1, dt_cv_scores[i]))
[0.8 0.84444444 0.81666667 0.8 0.78333333 0.86111111
0.88333333 0.79888268 0.81564246 0.77094972]
[0.77222222 0.86111111 0.83333333 0.76666667 0.79444444 0.88888889
0.87777778 0.81005587 0.78212291 0.81564246]
[0.78333333 0.85555556 0.85 0.78888889 0.78333333 0.88888889
0.86111111 0.80446927 0.82122905 0.81005587]
[0.75555556 0.83333333 0.81666667 0.79444444 0.77777778 0.89444444
0.9 0.80446927 0.82122905 0.81564246]
[0.8 0.83333333 0.83888889 0.76111111 0.78333333 0.87777778
0.89444444 0.84916201 0.81005587 0.81005587]
[0.77777778 0.82777778 0.82777778 0.8 0.79444444 0.88333333
0.91111111 0.82122905 0.7877095 0.81005587]
[0.78333333 0.83888889 0.83888889 0.77222222 0.77222222 0.88888889
0.87777778 0.81564246 0.81564246 0.80446927]
[0.8 0.83888889 0.84444444 0.79444444 0.8 0.88888889
0.86111111 0.84357542 0.79888268 0.80446927]
[0.78333333 0.82777778 0.81111111 0.80555556 0.79444444 0.86111111
0.88333333 0.84357542 0.77653631 0.79329609]
[0.80555556 0.85555556 0.82777778 0.78888889 0.78333333 0.88333333
0.86666667 0.80446927 0.82681564 0.79888268]
1 : 0.81744
2 : 0.82023
3 : 0.82469
4 : 0.82136
5 : 0.82582
6 : 0.82412
7 : 0.82080
8 : 0.82747
9 : 0.81801
10 : 0.82413
Image('./data/nfold.png', width=900)
#노랑색 : 자료분석, 하얀색 : 테스트

#랜덤 포레스트의 MNIST 손글씨 검증 정확도를 계산한다.
#의사결정 트리의 MNIST 손글씨 검증 정확도를 계산한다.
rf_cv_scores = cross_validation(RandomForestClassifier(), features, labels)
for i in range(len(dt_cv_scores)):
print('{0:2d} : {1:7.5f}'.format(i+1, rf_cv_scores[i]))
[0.91111111 0.97777778 0.95 0.91666667 0.95555556 0.96666667
0.97222222 0.96648045 0.94413408 0.93854749]
[0.88888889 0.96666667 0.94444444 0.92777778 0.95555556 0.96666667
0.98333333 0.97765363 0.9273743 0.9273743 ]
[0.9 0.97222222 0.95555556 0.93333333 0.96666667 0.97222222
0.97222222 0.96648045 0.95530726 0.93296089]
[0.90555556 0.97222222 0.94444444 0.91111111 0.97222222 0.96666667
0.98333333 0.96089385 0.94972067 0.9273743 ]
[0.90555556 0.97777778 0.95 0.92222222 0.95555556 0.96666667
0.98888889 0.96648045 0.92178771 0.94413408]
[0.92222222 0.97222222 0.93888889 0.92222222 0.96666667 0.97222222
0.96666667 0.96648045 0.93296089 0.93854749]
[0.90555556 0.97777778 0.93888889 0.90555556 0.96666667 0.96666667
0.97777778 0.95530726 0.95530726 0.94413408]
[0.90555556 0.97222222 0.95 0.93333333 0.95555556 0.97777778
0.97777778 0.96648045 0.92178771 0.92178771]
[0.90555556 0.97222222 0.95555556 0.92222222 0.96666667 0.96111111
0.98333333 0.96089385 0.94972067 0.93296089]
[0.91666667 0.98333333 0.93888889 0.91666667 0.96666667 0.96666667
0.98333333 0.94972067 0.9273743 0.93296089]
1 : 0.94992
2 : 0.94657
3 : 0.95270
4 : 0.94935
5 : 0.94991
6 : 0.94991
7 : 0.94936
8 : 0.94823
9 : 0.95102
10 : 0.94823
cv_dict = {'decision': dt_cv_scores, 'random_forest' : rf_cv_scores}
#df=pd.DataFrame.from_dict(cv_dict)
df=pd.DataFrame(cv_dict)
df
| decision | random_forest | |
|---|---|---|
| 0 | 0.817436 | 0.949916 |
| 1 | 0.820227 | 0.946574 |
| 2 | 0.824687 | 0.952697 |
| 3 | 0.821356 | 0.949354 |
| 4 | 0.825816 | 0.949907 |
| 5 | 0.824122 | 0.949910 |
| 6 | 0.820798 | 0.949364 |
| 7 | 0.827471 | 0.948228 |
| 8 | 0.818007 | 0.951024 |
| 9 | 0.824128 | 0.948228 |
df.plot()
<AxesSubplot:>
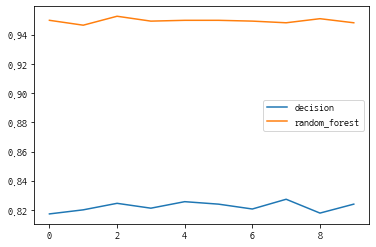
print('의사결정 트리 : {}'.format(np.mean(dt_cv_scores)))
print('랜덤 포레스트 : {}'.format(np.mean(rf_cv_scores)))
의사결정 트리 : 0.8224047175667287
랜덤 포레스트 : 0.94952017380509
댓글남기기