2_넘파이2
# jupyter notebook에서 경고 메시지 숨기기
# jupyter notebook을 사용하다 보면 향후 버전이 올라갈 때 변경 사항을
# 알려주는 경고 메시지가 출력되는데 눈에 거슬린다.
# 이럴 때 아래의 코드를 실행하면 경고 메시지가 출력되지 않는다.
import warnings
#경고 메세지를 표시하지 않는다. 다시 표시하지 않으려면
#default로 놓아야 한다.
warnings.filterwarnings('ignore')
from IPython.display import Image
Image('./numpyImages/numpyImage00.jpg', width=1200)

파이썬 기반 데이터 분석 환경에서 넘파이는 행렬(배열) 연산을 위한 핵심 라이브러리 이다.넘파이는 대규모 다차원 배열과 행렬 연산에 필요한 다양한 함수를 제공하고 특히 메모리 버퍼에 배열 데이터를 저장하고 처리하는 효율적인 인터펭스를 제공한다. 파이썬 리스트 객체를 개선한 넘파이 ndarray객체를 사용하면 더 많은 데이터를 더 빠르게 처리할 수 있다.
numpy의 특징
1. 강력한 n차원 배열 객체
2. 정교한 브로드캐스팅(다대일 연산) 가능
3. c/c++ 및 fortran 코드 통함 도구
4. 유연한 선형 대수학, 푸리에 변환 및 난수 기능
5. 범용적 데이터 처리에 사용 가능한 다차원 컨테이터
#jupyter notebook에서 CMD창으로 나가지 않고
#외부 라이브러리를 설치할 수 있다.
#=>pip앞에 '!'를 붙여서 실행할 수 있다.
#!pip install numpy
import numpy as np
print(np.__version__)
1.19.5
넘파이 데이터 타입
#넘파이는 다음과 같은 데이터 타입을 지원하고 배열을 생성할 때
#아래와 같은 데이터 타입을 지정할 수 있다.
#np.int : 정수(int8, int32, int64), int32가 기본값
#np.float : 실수(float32, float64)
#np.complex : 복소수
#np.bool : 불린(논리값ed changes)
#np.object : 객체
#np.string : 문자열
#np.unicode : 유니코드
#넘파이는 다차원 배열을 지원하고 넘파이 배열의
#구조는 shape으로 표현한다.
#shape은 배열의 구조를 튜플 자료형으로 사용해서
#표현한다.
#예시) 28*28 컬러 사진의 각 픽셀 3개의
#채널(RGB)로 구성된 구조를 가진다. 따라서 컬러
#사진의 데이터 구조는 shape(28,28,3)인 3차원 배열이
#된다. 다처원 배열은 입체적인 구조를 가지며 데이터의
#차원은 여러 갈래의 데이터 방향(axis)을 가진다.
#다차원 배열의 데이터 방향은 axis로 표현하고
#면은 axis=0. 행은 axis=1, 열은 axis=2로 지정한다.
Image(‘./numpyImages/numpyImage01.jpg’, width=1200)
#넘파이 배열 객체 정보 출력용으로 사용할 함수를 정의한다.
def pprint(arr):
print('type : {}'.format(type(arr)))
print('shape : {}, dimension : {}, dtype : {}'.format(arr.shape, arr.ndim, arr.dtype))
print('넘파이 배열에 저장된 데이터\n', arr)
파이썬 리스트 객체로 넘파이 배열을 생성할 수 있다. 인수로 리스트 객체와 데이터 타입(dtype)을 입력해서 넘파이 배열을 생성하고 dtype을 생략하면 입력되는 리스트 객체의 데이터 타입으로 넘파이 배열의 타입이 설정된다.
#파이썬 1차원 리스트로 넘파이 배열만들기.
arr=[1,2,3]
print(type(arr))
print(arr)
#넘파이의 array()함수는 파이썬 리스트 객체를 넘겨받아
#넘파이 배열을 생성한다.
a = np.array(arr, dtype=np.int)
pprint(a)
<class 'list'>
[1, 2, 3]
type : <class 'numpy.ndarray'>
shape : (3,), dimension : 1, dtype : int32
넘파이 배열에 저장된 데이터
[1 2 3]
#파이썬 2차원 리스트로 넘파이 배열 만들기
arr=[[1,2,3], [4,5,6]]
print(type(arr))
print(arr)
a=np.array(arr, dtype=np.float64)
pprint(a)
<class 'list'>
[[1, 2, 3], [4, 5, 6]]
type : <class 'numpy.ndarray'>
shape : (2, 3), dimension : 2, dtype : float64
넘파이 배열에 저장된 데이터
[[1. 2. 3.]
[4. 5. 6.]]
#파이썬 3차원 리스트로 넘파이 배열 만들기
arr=[ [[1,2,3], [4,5,6]],[[11,22,33], [44,55,66]]]
print(type(arr))
print(arr)
a=np.array(arr, dtype=np.int)
pprint(a)
<class 'list'>
[[[1, 2, 3], [4, 5, 6]], [[11, 22, 33], [44, 55, 66]]]
type : <class 'numpy.ndarray'>
shape : (2, 2, 3), dimension : 3, dtype : int32
넘파이 배열에 저장된 데이터
[[[ 1 2 3]
[ 4 5 6]]
[[11 22 33]
[44 55 66]]]
넘파이는 원하는 shape으로 배열을 만들고 각 요소를 특정값으로 초기화하는 함수를 제공한다.
#zeros()함수는 지정된 shape의 배열을 생성하고 모든
#요소를 0으로 초기화시킨다.
#zeros(shape, dtype, order)
#order => 다차원 데이터를 행 우선 방식(c/c++, java, python)(기본값),
# 열 우선 방식(fortran)으로 메모리에 저장할지 여부를 결정한다.
a = np.zeros(shape=(3,4), dtype=np.int, order="f")
pprint(a)
type : <class 'numpy.ndarray'>
shape : (3, 4), dimension : 2, dtype : int32
넘파이 배열에 저장된 데이터
[[0 0 0 0]
[0 0 0 0]
[0 0 0 0]]
#ones()함수는 지정된 shape의 배열을 생성하고 모든
#요소를 1으로 초기화시킨다.
#ones(shape, dtype, order)
#order => 다차원 데이터를 행 우선 방식(c/c++, java, python)(기본값),
# 열 우선 방식(fortran)으로 메모리에 저장할지 여부를 결정한다.
a = np.ones(shape=(3,4), dtype=np.float)
pprint(a)
type : <class 'numpy.ndarray'>
shape : (3, 4), dimension : 2, dtype : float64
넘파이 배열에 저장된 데이터
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
#full()함수는 지정된 shape의 배열을 생성하고 모든
#요소를 특정값(fill_value)으로 초기화시킨다.
#full(shape,fill_value,dtype,order)
#order => 다차원 데이터를 행 우선 방식(c/c++, java, python)(기본값),
# 열 우선 방식(fortran)으로 메모리에 저장할지 여부를 결정한다.
a = np.full(shape=(3,4), fill_value=999.)
pprint(a)
type : <class 'numpy.ndarray'>
shape : (3, 4), dimension : 2, dtype : float64
넘파이 배열에 저장된 데이터
[[999. 999. 999. 999.]
[999. 999. 999. 999.]
[999. 999. 999. 999.]]
#eye() 함수는 shpae이 (n,n)인 단위행렬(대각선 요소만 1이고 나머진 0)을 생성한다.
#eye(n)
a = np.eye(5)
pprint(a)
type : <class 'numpy.ndarray'>
shape : (5, 5), dimension : 2, dtype : float64
넘파이 배열에 저장된 데이터
[[1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1.]]
#empty() 함수는 지정된 shape의 빈 배열을 만든다.
#=>초기화를 하지 않는다. 쓰레기 값이 들어있다.
#empty(shape, dtype, order)
b = np.empty(shape=(3,4))
pprint(b)
type : <class 'numpy.ndarray'>
shape : (3, 4), dimension : 2, dtype : float64
넘파이 배열에 저장된 데이터
[[999. 999. 999. 999.]
[999. 999. 999. 999.]
[999. 999. 999. 999.]]
#like 함수
#넘파이는 인수로 지정된 배열과 shape이 같은 배열을 만드는
#*_like()함수를 제공한다.
#zeros_like(), ones_like(), full_like(), empty_like()
a = np.array([[1,2,3,], [11,22,33]])
pprint(a)
b=np.zeros_like(a)
pprint(b)
c=np.ones_like(a)
pprint(c)
d=np.full_like(a, 777)
pprint(d)
e=np.empty_like(a)
pprint(e)
type : <class 'numpy.ndarray'>
shape : (2, 3), dimension : 2, dtype : int32
넘파이 배열에 저장된 데이터
[[ 1 2 3]
[11 22 33]]
type : <class 'numpy.ndarray'>
shape : (2, 3), dimension : 2, dtype : int32
넘파이 배열에 저장된 데이터
[[0 0 0]
[0 0 0]]
type : <class 'numpy.ndarray'>
shape : (2, 3), dimension : 2, dtype : int32
넘파이 배열에 저장된 데이터
[[1 1 1]
[1 1 1]]
type : <class 'numpy.ndarray'>
shape : (2, 3), dimension : 2, dtype : int32
넘파이 배열에 저장된 데이터
[[777 777 777]
[777 777 777]]
type : <class 'numpy.ndarray'>
shape : (2, 3), dimension : 2, dtype : int32
넘파이 배열에 저장된 데이터
[[2100565312 456 0]
[ 0 1 2037544051]]
#넘파이는 주어진 조건으로 데이터를 생성한 후 배열을 만드는 데이터 생성 함수를 제공한다.
#linspace(), arange(), logspace()
# !pip install matplotlib
import matplotlib.pyplot as plt
#linspace()함수는 start부터 stop의 범위에서 num개를 균일한 간격으로
#데이터를 생성해서 배열을 만든다.
#linspace(start, stop, num)
#요소의 개수를 기준으로 균등 간격 배열을 생성한다.
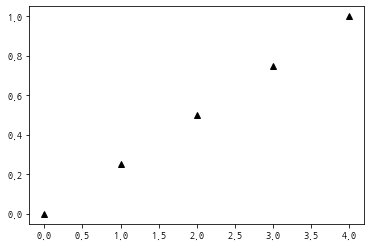
a = np.linspace(0,1,5)
pprint(a)
#linspace()함수 실행 결과 시각화
#o => 동그라미, s => 사각형, * => 별, '^'=> 삼각형
#모양 미설정시 선으로 그래프가 표시된다.
#b(blue), white(w), m(magenta), y(yellow), g(green), r(red)등등
#색깔과 표시의 모양 순서는 바뀌어도 된다.
plt.plot(a,'^k')
plt.show()
type : <class 'numpy.ndarray'>
shape : (5,), dimension : 1, dtype : float64
넘파이 배열에 저장된 데이터
[0. 0.25 0.5 0.75 1. ]
# arange()함수는 start부터 stop미만까지 step간격으로 데이터를 생성하고
# 배열을 만든다.
# arange([start, ] stop[, stop])
#linspace()함수는 요소의 개수로 배열을 만들었지만 arrange()함수는 데이터
#간격을 기준으로 균등한 간격의 배열을 생성한다.
#start를 생략하면 0, step을 생략하면 1이 기본값으로 사용된다.
#arange(10), arange(0, 10), arange(0,10,1)은 모드 같은 기능이 실행된다.
#a = np.arange(0,10), a = np.arange(0,10,1)
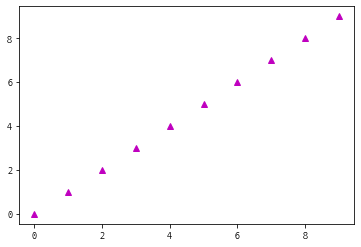
a = np.arange(10)
pprint(a)
#arange()함수 실행결과
plt.plot(a, 'm^')
plt.show()
type : <class 'numpy.ndarray'>
shape : (10,), dimension : 1, dtype : int32
넘파이 배열에 저장된 데이터
[0 1 2 3 4 5 6 7 8 9]
#logspace()함수는 로그 스케일로 지정된 범위(start 부터 stop사이)에서 num개 만큼
#균등 간격으로 데이터를 생성하고 배열을 만든다.
#logspace(start, stop, num, base)
#num이 승수, base가 밑수다.
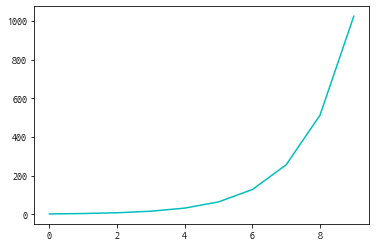
a = np.logspace(1,10, num=10, base=2)
pprint(a)
plt.plot(a, 'c')
plt.show()
type : <class 'numpy.ndarray'>
shape : (10,), dimension : 1, dtype : float64
넘파이 배열에 저장된 데이터
[ 2. 4. 8. 16. 32. 64. 128. 256. 512. 1024.]
난수 기반 배열 생성
#넘파이는 난수 발생 및 배열을 생성하는 random 모듈을 제공하고 다음과 같은
#함수를 사용할 수 있다.
#normal(), randn(), rand(), randint(), random()
#normal() 함수는 정규 분포를 따르는 난수로 데이터를 생성하고
#배열을 만든다.
#normal(정규 분포의 평균, 표준편차, 난수의 개수)
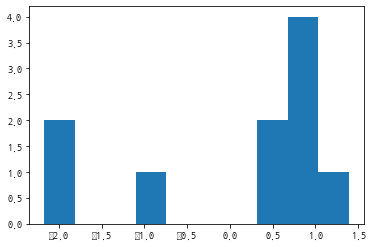
a= np.random.normal(0, 1, 10)
pprint(a)
#히스토그램을 만들어서 확인한다.
plt.hist(a)
plt.show()
type : <class 'numpy.ndarray'>
shape : (10,), dimension : 1, dtype : float64
넘파이 배열에 저장된 데이터
[ 0.46644067 0.97857314 0.56434609 1.0279773 0.75827517 -2.16853885
1.38918362 0.77254476 -1.95025945 -0.74851902]
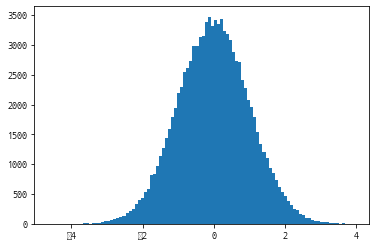
#normal()함수가 생성한 난수는 정규 분포의 형상을 가진다.
a= np.random.normal(0, 1, 100000)
pprint(a)
#정규 분포에서 100,000개의 표본을 뽑은 결과를 100개의 구간
#(bins)으로 구분한 히스토그램으로 표현한다.
plt.hist(a, bins=100)
plt.show()
type : <class 'numpy.ndarray'>
shape : (100000,), dimension : 1, dtype : float64
넘파이 배열에 저장된 데이터
[ 1.30426319 -0.21954519 1.24192054 ... -0.23179002 -1.16816648
-2.47179796]
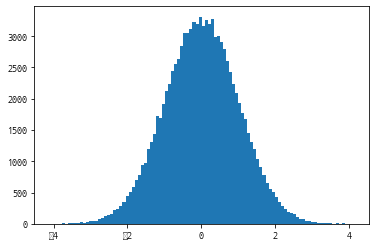
# randn()함수는 표준 정규 분포(평균이 0이고 표준편차가1)를 따르는
# 난수 데이터를 생성하고 배열을 만든다.
# randn(난수의 개수)
a = np.random.randn(100000)
pprint(a)
plt.hist(a, bins=100)
plt.show()
type : <class 'numpy.ndarray'>
shape : (100000,), dimension : 1, dtype : float64
넘파이 배열에 저장된 데이터
[-0.19607769 -1.14956864 -0.0329812 ... 0.92935058 -0.04355558
-0.38435659]
# rand()함수는 0~1사이의 균등 분포를 따르는 난수로 데이터를 생성하고
# 배열을 만든다.
# np.random.rand(난수의 개수)
a = np.random.rand(3,2)
pprint(a)
plt.hist(a)
plt.show()
type : <class 'numpy.ndarray'>
shape : (3, 2), dimension : 2, dtype : float64
넘파이 배열에 저장된 데이터
[[0.6692633 0.80832011]
[0.32022096 0.34939303]
[0.61749953 0.60774875]]
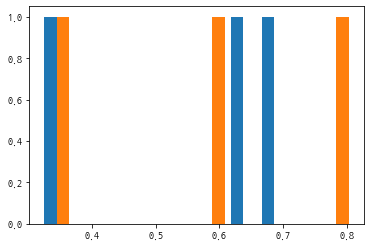
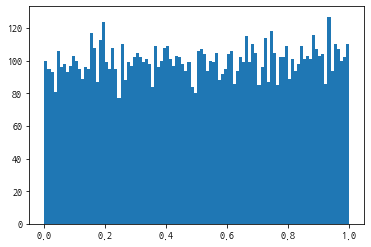
#rand()함수가 생성한 난수는 균등 분포의 형상을 가진다.
a = np.random.rand(10000)
pprint(a)
plt.hist(a, bins=100)
plt.show()
type : <class 'numpy.ndarray'>
shape : (10000,), dimension : 1, dtype : float64
넘파이 배열에 저장된 데이터
[0.19172463 0.37916469 0.67070867 ... 0.66810986 0.7521906 0.93288593]
# randint()함수는 지정된 크기만큼 low부터 high미만의 범위에서
# 정수로 난수 데이터를 생성하고 배열을 만든다.
# randint(low, high, 난수의 개수)
a = np.random.randint(1,46,6)
pprint(a)
type : <class 'numpy.ndarray'>
shape : (6,), dimension : 1, dtype : int32
넘파이 배열에 저장된 데이터
[11 26 30 33 31 12]
# -100에서 100의 범위에서 난수를 발생시킨다.(균등분포)
a = np.random.randint(-100, 100, 10000)
pprint(a)
plt.hist(a)
plt.show()
type : <class 'numpy.ndarray'>
shape : (10000,), dimension : 1, dtype : int32
넘파이 배열에 저장된 데이터
[ 70 -23 -34 ... 45 -50 31]
#random()함수는 0~1사이의 균등 분포에서 난수로 데이터를
#생성하고 배열을 만든다.(rand()와 다르다.)
#배열의 크기를 2차원 이상으로 지정하려면 ()로 묶어서 지정해야 한다.
a = np.random.random((2,4))
pprint(a)
a = np.random.random(100000)
plt.hist(a)
plt.show()
type : <class 'numpy.ndarray'>
shape : (2, 4), dimension : 2, dtype : float64
넘파이 배열에 저장된 데이터
[[0.56862505 0.0652363 0.41071345 0.92317253]
[0.77149013 0.89775728 0.61870235 0.9396819 ]]

약속된 난수
#무작위 수를 만드는 난수는 특정 시작 숫자로부터 난수처럼
#보이는 수열을 만드는 알고리즘의 결과물이다.
#따라서 시작점을 고정하면 난수 발생을 재연할 수 있다.
#=>매번 같은 난수가 발생되게 할 수 있다.
#seed()함수로 seed값을 지정하면 매번 같은 배열의 난수를
#얻을 수 있다.
#아래 괄호안의 숫자는 큰 의미는 없다.
np.random.seed(50)
pprint(np.random.randint(0,10,(2,3)))
pprint(np.random.randint((2,3)))
type : <class 'numpy.ndarray'>
shape : (2, 3), dimension : 2, dtype : int32
넘파이 배열에 저장된 데이터
[[0 0 1]
[4 6 5]]
type : <class 'numpy.ndarray'>
shape : (2,), dimension : 1, dtype : int32
넘파이 배열에 저장된 데이터
[0 2]
# numpy는 배열의 상태를 검사하는 다음과 같은 방법을 제공한다.
# 배열 속성 검사 항목 배열 속성 확인 방법 예시 결과
# 배열 shape np.ndarray.shape 속성 arr.shape (5, 2, 3)
# 배열 길이 일차원 배열 길이 확인 len(arr) 5
# 배열 차원 np.ndarray.ndim 속성 arr.ndim 3
# 배열 요소 수 np.ndarray.size 속성 arr.size 30
# 배열 타입 np.ndarray.dtype 속성 arr.dtype dtype('float64')
# 배열 타입 명 np.ndarray.dtype.name 속성 arr.dtype.name float64
# 배열 타입 변환 np.ndarray.astype 속성 arr.astype(np.int) 배열 타입 변환
arr = np.random.random((2,3,6))
pprint(arr)
type : <class 'numpy.ndarray'>
shape : (2, 3, 6), dimension : 3, dtype : float64
넘파이 배열에 저장된 데이터
[[[0.95470613 0.80468256 0.24423009 0.3251973 0.43930505 0.13478847]
[0.59472326 0.97821597 0.08861251 0.29394091 0.23904398 0.51661166]
[0.04597103 0.26465872 0.67136671 0.78927019 0.36441934 0.11342968]]
[[0.16679188 0.01824974 0.78856948 0.27714299 0.86507366 0.52872064]
[0.69292202 0.05274132 0.77317277 0.20118524 0.01749162 0.31797437]
[0.67441032 0.27666963 0.20606164 0.8856327 0.7314353 0.9259965 ]]]
#넘파이 배열 객체는 다음과 같은 방법으로 속성을 확인할 수 있다.
print('배열의 타입 : {}'.format(type(arr)))
print('배열의 shpae : {}'.format(arr.shape))
print('배열의 길이(면) : {}'.format(len(arr)))
print('배열의 길이(행) : {}'.format(len(arr[0])))
print('배열의 길이(열) : {}'.format(len(arr[0][0])))
print('배열의 차원 : {}'.format(arr.ndim))
print('배열의 차원 : {}'.format(arr.size))
print('배열에 저장된 데이터 타입 : {}'.format(arr.dtype))
print('배열에 저장된 데이터 타입의 이름: {}'.format(arr.dtype.name))
#배열의 요소를 정수(int)로 변환한다.
#=>배열 요소들의 실제 값이 변환되는 것이
# 아니고 화면에 보여주기만 하는 것이다.
print(arr.astype(np.int32))
print(arr)
#실제 데이터가 변경되게 하려면 정수로 변호나한 결과를
#배열에 다시 저장하면 된다.
arr = arr.astype(np.int32)
print(arr)
배열의 타입 : <class 'numpy.ndarray'>
배열의 shpae : (2, 3, 6)
배열의 길이(면) : 2
배열의 길이(행) : 3
배열의 길이(열) : 6
배열의 차원 : 3
배열의 차원 : 36
배열에 저장된 데이터 타입 : float64
배열에 저장된 데이터 타입의 이름: float64
[[[0 0 0 0 0 0]
[0 0 0 0 0 0]
[0 0 0 0 0 0]]
[[0 0 0 0 0 0]
[0 0 0 0 0 0]
[0 0 0 0 0 0]]]
[[[0.95470613 0.80468256 0.24423009 0.3251973 0.43930505 0.13478847]
[0.59472326 0.97821597 0.08861251 0.29394091 0.23904398 0.51661166]
[0.04597103 0.26465872 0.67136671 0.78927019 0.36441934 0.11342968]]
[[0.16679188 0.01824974 0.78856948 0.27714299 0.86507366 0.52872064]
[0.69292202 0.05274132 0.77317277 0.20118524 0.01749162 0.31797437]
[0.67441032 0.27666963 0.20606164 0.8856327 0.7314353 0.9259965 ]]]
[[[0 0 0 0 0 0]
[0 0 0 0 0 0]
[0 0 0 0 0 0]]
[[0 0 0 0 0 0]
[0 0 0 0 0 0]
[0 0 0 0 0 0]]]
댓글남기기