3_넘파이3
import warnings
warnings.filterwarnings('ignore')
from IPython.display import Image
import numpy as np
#넘파이 배열 객체 정보 출력용으로 사용할 함수를 정의한다.
def pprint(arr):
print('type : {}'.format(type(arr)))
print('shape : {}, dimension : {}, dtype : {}'.format(arr.shape, arr.ndim, arr.dtype))
print('넘파이 배열에 저장된 데이터\n', arr)
넘파이 배열 파일 입출력
# numpy는 배열 객체를 바이너리 파일 또는 텍스트 파일에 저장하고 로딩하는 기능을 제공한다.
# 메소드 이름 기능 파일포맷
# np.save() numpy 배열 객체 1개를 파일에 저장한다. 바이너리
# np.savez() numpy 배열 객체 여러개를 파일에 저장한다. 바이너리
# np.load() numpy 배열 저장 파일로 부터 객체를 읽어온다. 바이너리
# np.savetxt() numpy 배열 객체를 텍스트 파일에 저장한다. 텍스트 => txt(X), csv, tsv(O)
# np.loadtxt() 텍스트 파일에 저장된 numpy 배열 객체를 읽어온다. 텍스트
# csv => comma seperated value, tsv=>tab seperated value;
np.random.seed(100)
a = np.random.randint(1, 10, (2,3))
pprint(a)
b = np.random.randint(1, 10, (2,3))
pprint(b)
type : <class 'numpy.ndarray'>
shape : (2, 3), dimension : 2, dtype : int32
넘파이 배열에 저장된 데이터
[[9 9 4]
[8 8 1]]
type : <class 'numpy.ndarray'>
shape : (2, 3), dimension : 2, dtype : int32
넘파이 배열에 저장된 데이터
[[5 3 6]
[3 3 3]]
#배열 객체 저장 - 바이너리 파일
#save(), savez() 함수를 이용해서 배열 객체를 바이너리(2진)
#형태의 파일로 저장할 수 있다.
#save('파일이름(경로포함)', '배열이름') : 배열 한개를 저장한다. 확장명 => npy
#savez('파일이름(경로포함)', '배열이름1', '배열이름2', ....) : 배열 여러개를 저장한다. 확장명 => npz
#a 배열을 파일로 저장한다.
np.save('./output/my_array1', a)
#a,b 배열을 파일로 저장한다.
np.savez('./output/my_array2', a,b)
#load()함수로 npy, npz파일로부터 배열 데이터를 읽어올 수 있다.
#확장명을 반드시 적어야 한다.
#npy파일 읽기
print(np.load('./output/my_array1.npy'))
#npz파일 읽기
print(np.load('./output/my_array2.npz'))
npzFile = np.load('./output/my_array2.npz')
#정해진 이름(arr_0,arr_1,....arr_n을 써야한다.)
print(npzFile['arr_0'])
print(npzFile['arr_1'])
[[9 9 4]
[8 8 1]]
<numpy.lib.npyio.NpzFile object at 0x0000025CF97BDEF0>
[[9 9 4]
[8 8 1]]
[[5 3 6]
[3 3 3]]
data = np.random.random((3,4))
pprint(data)
type : <class 'numpy.ndarray'>
shape : (3, 4), dimension : 2, dtype : float64
넘파이 배열에 저장된 데이터
[[0.13670659 0.57509333 0.89132195 0.20920212]
[0.18532822 0.10837689 0.21969749 0.97862378]
[0.81168315 0.17194101 0.81622475 0.27407375]]
#배열 객체 저장 - 텍스트 파일
#savetext() 함수로 배열 객체를 텍스트 파일로 저장할 수 있다.
#=>csv, tsv파일
#savetext('파일 이름', 데이터, delimiter='구분자')
#data 배열을 텍스트 파일로 저장한다
#np.savetxt('./output/saved.csv', data)
#구분자를 생략하면 기본으로 csv(엑셀)파일로 저장한다.
np.savetxt('./output/saved.csv', data, delimiter=',')
np.savetxt('./output/saved.tsv', data, delimiter='\t')
#loadtxt() 함수로 csv, tsc 파일로부터 배열 데이터를 읽어올 수 있다.
#구분자 반드시 써주자.
#loadtxt('파일 이름', delimiter='구분자')
print(np.loadtxt('./output/saved.csv', delimiter=','))
print(np.loadtxt('./output/saved.tsv', delimiter='\t'))
[[0.13670659 0.57509333 0.89132195 0.20920212]
[0.18532822 0.10837689 0.21969749 0.97862378]
[0.81168315 0.17194101 0.81622475 0.27407375]]
[[0.13670659 0.57509333 0.89132195 0.20920212]
[0.18532822 0.10837689 0.21969749 0.97862378]
[0.81168315 0.17194101 0.81622475 0.27407375]]
배열(행렬)연산 - 산술연산
a = np.arange(1, 10).reshape(3,3)
print(a)
b = np.arange(9, 0, -1).reshape(3,3)
print(b)
[[1 2 3]
[4 5 6]
[7 8 9]]
[[9 8 7]
[6 5 4]
[3 2 1]]
#덧셈 : +, add()
print(a+b)
print(np.add(a,b))
[[10 10 10]
[10 10 10]
[10 10 10]]
[[10 10 10]
[10 10 10]
[10 10 10]]
#뺄셈 : -, subtract()
print(a-b)
print(np.subtract(a,b))
[[-8 -6 -4]
[-2 0 2]
[ 4 6 8]]
[[-8 -6 -4]
[-2 0 2]
[ 4 6 8]]
#곱셈 : *, multiply() => 각 요소끼리의 곱
print(a*b)
print(np.multiply(a,b))
[[ 9 16 21]
[24 25 24]
[21 16 9]]
[[ 9 16 21]
[24 25 24]
[21 16 9]]
#나눗셈 : /, divide() => 각 요소끼리의 나눗셈
print(a/b)
print(np.divide(a,b))
[[0.11111111 0.25 0.42857143]
[0.66666667 1. 1.5 ]
[2.33333333 4. 9. ]]
[[0.11111111 0.25 0.42857143]
[0.66666667 1. 1.5 ]
[2.33333333 4. 9. ]]
#지수의 형태로 값 표현
print(np.exp(a))
[[2.71828183e+00 7.38905610e+00 2.00855369e+01]
[5.45981500e+01 1.48413159e+02 4.03428793e+02]
[1.09663316e+03 2.98095799e+03 8.10308393e+03]]
#제곱근
print(np.sqrt(a))
[[1. 1.41421356 1.73205081]
[2. 2.23606798 2.44948974]
[2.64575131 2.82842712 3. ]]
#삼각함수
print(np.sin(a))
print(np.cos(a))
print(np.tan(a))
[[ 0.84147098 0.90929743 0.14112001]
[-0.7568025 -0.95892427 -0.2794155 ]
[ 0.6569866 0.98935825 0.41211849]]
[[ 0.54030231 -0.41614684 -0.9899925 ]
[-0.65364362 0.28366219 0.96017029]
[ 0.75390225 -0.14550003 -0.91113026]]
[[ 1.55740772 -2.18503986 -0.14254654]
[ 1.15782128 -3.38051501 -0.29100619]
[ 0.87144798 -6.79971146 -0.45231566]]
#로그
print(np.log(a))
[[0. 0.69314718 1.09861229]
[1.38629436 1.60943791 1.79175947]
[1.94591015 2.07944154 2.19722458]]
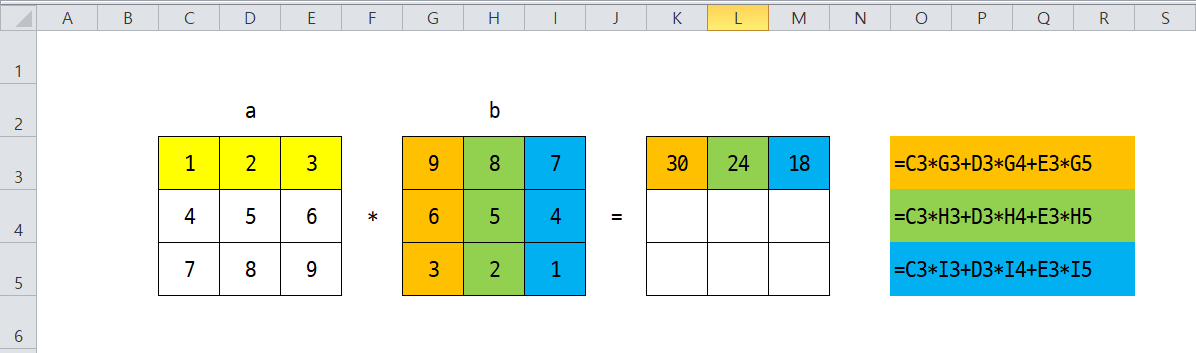
#행렬의 내정 => 행렬의 곱
print(np.dot(a,b))
Image('./numpyImages/matrix.png', width =1000)
[[ 30 24 18]
[ 84 69 54]
[138 114 90]]
비교 연산
#배열 요소별 비교 : >,<,>=, <=, ==, !=
print(a==b)
[[False False False]
[False True False]
[False False False]]
#array_equal()함수를 사용하면 배열 전체를 비교할 수 있다.
print(np.array_equal(a,b))
False
#집계 함수
#넘파이의 거의 모든 집계 함수는 axis를 기준으로 계산된다.
#집계 함수에 axis를 지정하지 않으면, axis=None이 기본값으로
#사용된다.
#axis=None, axis=0, axis=1과 같이 지정한다.
a = np.arange(1,10).reshape(3,3)
pprint(a)
type : <class 'numpy.ndarray'>
shape : (3, 3), dimension : 2, dtype : int32
넘파이 배열에 저장된 데이터
[[1 2 3]
[4 5 6]
[7 8 9]]
합계 : 배열.sum(axis), np.sum(배열, axis)
#axis = None 생략시 기본값
#axis = None은 전체 배열을 하나의 배열로 간주하고 집계 함수의
#범위를 전체 배열로 정의한다.
Image('./numpyImages/numpyImage02.jpg', width =200)
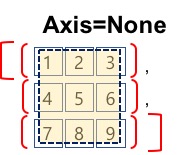
print(a.sum())
print(a.sum(axis=None))
print(np.sum(a))
print(np.sum(a, axis=None))
45
45
45
45
#axis=0 (0은 열)
#axis=0는 행을 기준으로 각 행의 동일한 인덱스 요소를
#그룹으로 연결한다. => 각 열의 합계
Image('./numpyImages/numpyImage03.jpg', width =200)
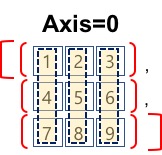
print(a.sum(axis=0))
print(np.sum(a,axis=0))
[12 15 18]
[12 15 18]
#axis=1 (1은 행)
#axis=1는 열을 기준으로 각 열의 동일한 인덱스 요소를
#그룹으로 연결한다. => 각 행의 합계
Image('./numpyImages/numpyImage04.jpg', width =200)
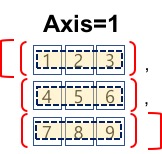
print(a.sum(axis=1))
print(np.sum(a,axis=1))
[ 6 15 24]
[ 6 15 24]
#최대값 : 배열.max(axis), np.max(배열, axis)
#최소값 : 배열.min(axis), np.min(배열, axis)
print(a.max())
print(np.max(a))
print(a.min())
print(np.min(a))
9
9
1
1
print(a.max(axis=0))
print(np.max(a,axis=0))
print(a.min(axis=0))
print(np.min(a,axis=0))
[7 8 9]
[7 8 9]
[1 2 3]
[1 2 3]
print(a.max(axis=1))
print(np.max(a,axis=1))
print(a.min(axis=1))
print(np.min(a,axis=1))
[3 6 9]
[3 6 9]
[1 4 7]
[1 4 7]
누적 합계 : 배열.cumsum(axis), np.cumsum(배열, axis)
print(a.cumsum())
print(np.cumsum(a))
[ 1 3 6 10 15 21 28 36 45]
[ 1 3 6 10 15 21 28 36 45]
print(a.cumsum(axis=0))
print(np.cumsum(a, axis=0))
[[ 1 2 3]
[ 5 7 9]
[12 15 18]]
[[ 1 2 3]
[ 5 7 9]
[12 15 18]]
print(a.cumsum(axis=1))
print(np.cumsum(a, axis=1))
[[ 1 3 6]
[ 4 9 15]
[ 7 15 24]]
[[ 1 3 6]
[ 4 9 15]
[ 7 15 24]]
평균 : 배열.mean(axis), np.mean(배열, axis)
print(a.mean())
print(np.mean(a))
5.0
5.0
print(a.mean(axis=0))
print(np.mean(a, axis=0))
[4. 5. 6.]
[4. 5. 6.]
중위수 : np.median(배열, axis),어떤 주어진 값들을 크기의 순서대로 정렬했을 때 가장 중앙에 위치하는 값
#print(a.median()) # 에러
print(np.median(a))
print(np.median(a, axis=0))
print(np.median(a, axis=1))
5.0
[4. 5. 6.]
[2. 5. 8.]
표준편차 : 배열.std(axis), np.std(배열, axis)
print(a.std())
print(np.std(a))
2.581988897471611
2.581988897471611
print(a.std(axis=0))
print(np.std(a, axis=0))
[2.44948974 2.44948974 2.44948974]
[2.44948974 2.44948974 2.44948974]
print(a.std(axis=1))
print(np.std(a, axis=1))
[0.81649658 0.81649658 0.81649658]
[0.81649658 0.81649658 0.81649658]
브로드캐스팅 => 다대일 연산
#shape이 같은 배열의 이항 연산은 배열 요소별로 실행된다.
#두 배열의 shape 다를 경우 배열의 형상을 맞추는 아래 그림과
#같은 브로드캐스팅 과정을 거처서 실행된다.
Image('./numpyImages/numpyImage05.jpg', width =1000)
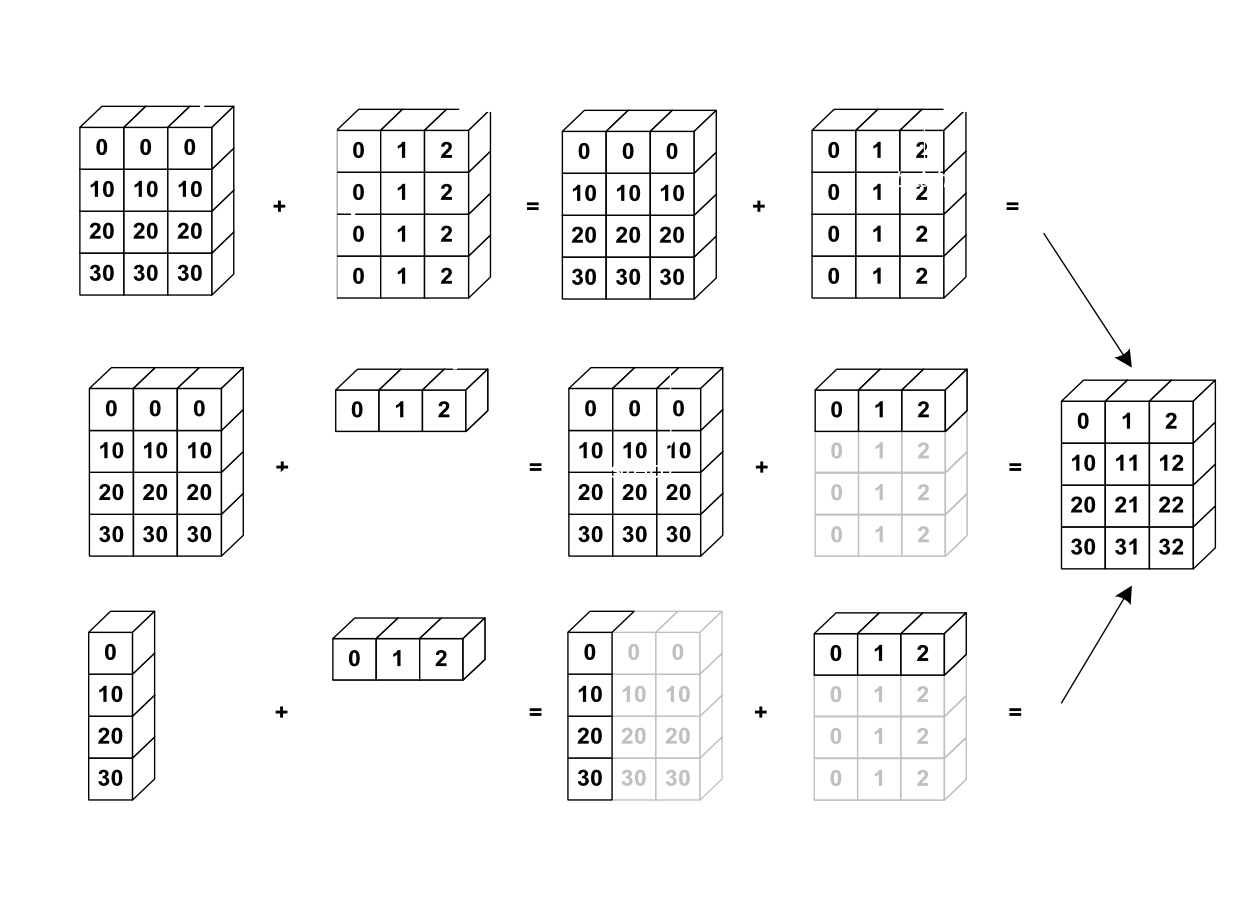
a=np.arange(1,25).reshape(4,6)
print(a)
b=np.arange(25,49).reshape(4,6)
print(b)
[[ 1 2 3 4 5 6]
[ 7 8 9 10 11 12]
[13 14 15 16 17 18]
[19 20 21 22 23 24]]
[[25 26 27 28 29 30]
[31 32 33 34 35 36]
[37 38 39 40 41 42]
[43 44 45 46 47 48]]
print(a+b)
[[26 28 30 32 34 36]
[38 40 42 44 46 48]
[50 52 54 56 58 60]
[62 64 66 68 70 72]]
#shape이 다른 배열의 연산
#shape이 다른 배열 사이의 이항 연산에서 브로드캐스팅 발생시 배열은
#같은 shape으로 만든 후 연산을 실행한다.
#case 1 : 배열과 스칼라(단일 값)의 연산
#배열과 스칼라 사이의 이항 연산시 스칼라를
#배열로 변환한다.
a=np.arange(1,25).reshape(4,6)
print(a)
print(a+100)
[[ 1 2 3 4 5 6]
[ 7 8 9 10 11 12]
[13 14 15 16 17 18]
[19 20 21 22 23 24]]
[[101 102 103 104 105 106]
[107 108 109 110 111 112]
[113 114 115 116 117 118]
[119 120 121 122 123 124]]
#a+100은 다음과 같은 과정을 거쳐 처리된다.
new_arr = np.full_like(a, 100)
print(new_arr)
print(a+new_arr)
[[100 100 100 100 100 100]
[100 100 100 100 100 100]
[100 100 100 100 100 100]
[100 100 100 100 100 100]]
[[101 102 103 104 105 106]
[107 108 109 110 111 112]
[113 114 115 116 117 118]
[119 120 121 122 123 124]]
#case 2 : shape이 다른 배열의 연산
a = np.arange(5).reshape(1,5)
print(a)
b = np.arange(5).reshape(5,1)
print(b)
print(a+b)
[[0 1 2 3 4]]
[[0]
[1]
[2]
[3]
[4]]
[[0 1 2 3 4]
[1 2 3 4 5]
[2 3 4 5 6]
[3 4 5 6 7]
[4 5 6 7 8]]
백터 연산
#넘파이는 백터 연산을 지원한다.
#넘파이의 집합 연산에서는 백터화 기능이 적용되어 있어서
#배열 처리에 대해 백터 연산을 적용할 경우 속도가 100배
#이상 빠르다.
#머신러닝에서 선형대수 연산을 처리할 때 매우 높은 효과
#(효율)을 낼 수 있다.
a = np.arange(1, 10000001, dtype=np.int64)
print(a)
[ 1 2 3 ... 9999998 9999999 10000000]
%%time
result = 0
for i in a:
result += i
print(result)
#%%time소요시간 알려준다.
[2997 15 18]
Wall time: 2.99 ms
%%time
result = np.sum(a)
print(result)
50000005000000
Wall time: 9.01 ms
#ndarray배열에 대한 인덱싱, 슬라이싱(subset)의 결과는 새로운
#배열이 아닌 원본 배열의 view이다.
#반환된 배열의 값을 변경하면 원본 배열에 변경한 내용이 반영된다.
#=>원본과 사본이 같은 메모리를 사용한다.
#따라서, 원본 배열로 부터 새로운 배열을 생성하기 위해서 copy()함수를
#사용한다.
#copy()함수로 복사한 배열은 원본 배열과 완전히 다른 별도의 배열이 된다.(깊은복사)
#슬라이싱 참조
import numpy as np
list1 =[[1,2,3,4],
[5,6,7,8]]
a=np.array(list1)
print(a[0:2,0:2])
[[1 2]
[5 6]]
a = np.arange(1,10).reshape(3,3)
print(a)
#행은 어떤 행이 나와도 상관없고(모든행)
#열은 무조건 0열을 슬라이싱 한다.
#[:]인덱스 0부터 끝까지 했던것 생각하자.
print(a[:,0])
a[:, 0] = 999
print(a)
print(a[:,0])
[[1 2 3]
[4 5 6]
[7 8 9]]
[1 4 7]
[[999 2 3]
[999 5 6]
[999 8 9]]
[999 999 999]
copied_a = np.copy(a)
print(copied_a)
print(copied_a[:, 1])
copied_a[:, 1] =777
print(copied_a[:, 1])
print(copied_a)
print(a)
[[999 2 3]
[999 5 6]
[999 8 9]]
[2 5 8]
[777 777 777]
[[999 777 3]
[999 777 6]
[999 777 9]]
[[999 2 3]
[999 5 6]
[999 8 9]]
배열 정렬
#ndarray 객체는 axis를 기준으로 요소를 정렬하는 sort()
#함수를 제공한다.
unsorted_arr = np.random.random((3,3))
print(unsorted_arr)
[[0.43170418 0.94002982 0.81764938]
[0.33611195 0.17541045 0.37283205]
[0.00568851 0.25242635 0.79566251]]
#정렬 작업을 위해 원본을 복사한다.
unsorted_arr1 = unsorted_arr.copy()
unsorted_arr2 = unsorted_arr.copy()
unsorted_arr3 = unsorted_arr.copy()
#배열.sort()
#sort()함수는 axis의 기본값이 None이 아니고
#-1이다.
#-1은 현재 배열의 마지막 axis를 의미하고
#unsorted_arr배열은 2차원이므로 마지막
#axis는 1이다.
#배열.sort()와 배열.sort(axis=-1), 배열.sort(axis=1)의 결과는 같다.
unsorted_arr1.sort()
print(unsorted_arr1)
[[0.43170418 0.81764938 0.94002982]
[0.17541045 0.33611195 0.37283205]
[0.00568851 0.25242635 0.79566251]]
unsorted_arr2.sort(axis=-1)
print(unsorted_arr1)
[[0.43170418 0.81764938 0.94002982]
[0.17541045 0.33611195 0.37283205]
[0.00568851 0.25242635 0.79566251]]
#행을 기준으로 정렬
unsorted_arr3.sort(axis=1)
print(unsorted_arr1)
[[0.43170418 0.81764938 0.94002982]
[0.17541045 0.33611195 0.37283205]
[0.00568851 0.25242635 0.79566251]]
#열을 기준으로 정렬
unsorted_arr1.sort(axis=0)
print(unsorted_arr1)
[[0.00568851 0.25242635 0.37283205]
[0.17541045 0.33611195 0.79566251]
[0.43170418 0.81764938 0.94002982]]
댓글남기기