4_넘파이4
import warnings
warnings.filterwarnings('ignore')
from IPython.display import Image
import numpy as np
#넘파이 배열 객체 정보 출력용으로 사용할 함수를 정의한다.
def pprint(arr):
print('type : {}'.format(type(arr)))
print('shape : {}, dimension : {}, dtype : {}'.format(arr.shape, arr.ndim, arr.dtype))
print('넘파이 배열에 저장된 데이터\n', arr)
인덱싱
#배열의 각 요소는 axis 인덱스로 참조할 수 있다.
#1차원 배열은 한개의 인덱스, 2차원 배열은 두개의 인덱스
#3차워 배열은 세개의 인덱스 요소를 참조할 수 있다.
#인덱싱 작업시 [행][열]과 같이 인덱스를 지정하거나
#[행,열]과 같이 인덱스를 지정할 수 있다.
#1차원 배열
a=np.arange(24)
print(a)
#1차원 배열 요소 참조 및 변경
print(a[5])
a[0] = 10000
print(a)
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
5
[10000 1 2 3 4 5 6 7 8 9 10 11
12 13 14 15 16 17 18 19 20 21 22 23]
#2차원 배열
a=np.arange(24).reshape(4,6)
print(a)
#2차원 배열 요소 참조 및 변경
print(a[0][1])
print(a[0,1])
a[0][1] = 1000
a[2][4] = 2000
print(a)
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]
1
1
[[ 0 1000 2 3 4 5]
[ 6 7 8 9 10 11]
[ 12 13 14 15 2000 17]
[ 18 19 20 21 22 23]]
#3차원 배열
a=np.arange(24).reshape(2,4,3)
print(a)
#3차원 배열 요소 참조 및 변경
print(a[0][2][1])
print(a[1,1,2])
a[0][2][1] = 99
a[1,1,2] =55
print(a)
[[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
[[12 13 14]
[15 16 17]
[18 19 20]
[21 22 23]]]
7
17
[[[ 0 1 2]
[ 3 4 5]
[ 6 99 8]
[ 9 10 11]]
[[12 13 14]
[15 16 55]
[18 19 20]
[21 22 23]]]
슬라이싱
#1차원 배열 슬라이싱
a = np.arange(24)
print(a)
print(a[2:6])
print(a[:6])
print(a[2:])
print(a[:])
print(a[::2])
print(a[::-1])
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
[2 3 4 5]
[0 1 2 3 4 5]
[ 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
[ 0 2 4 6 8 10 12 14 16 18 20 22]
[23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0]
#2차원 배열 슬라이싱
Image('./numpyImages/numpyImage06.jpg', width=800)

a=np.arange(1,25).reshape(4,6)
print(a)
[[ 1 2 3 4 5 6]
[ 7 8 9 10 11 12]
[13 14 15 16 17 18]
[19 20 21 22 23 24]]
#2차워 배열을 슬라이싱 할 열 때 모두를 슬라이싱하려면
#[]내부에 행과 열을 모두 입력해야 한다.
#print(a[1:3, :])
print(a[1:3]) #행 단위로 슬라이싱 하려면 열을 생략한다.
print(a[:, 1:5]) #열 단위로 슬라이싱 하려면 행에 ':'을 써야한다.
print(a[1:3, 1:5])
#아래와 같이 실행하면 a[1:3]가 먼저 실행된 결과에
#[1:5]을 행으로 인식해서 슬라이싱이 실행된다.
[[ 7 8 9 10 11 12]
[13 14 15 16 17 18]]
[[ 2 3 4 5]
[ 8 9 10 11]
[14 15 16 17]
[20 21 22 23]]
[[ 8 9 10 11]
[14 15 16 17]]
#슬라이싱 작업시 []를 연속해서 사용하면 앞의
#슬라이싱 결과를 가지고 뒤의 슬라이싱을 실행한다.
#아래와 같이 실행하면 a[1:3]가 먼저 실행된 결과에
#[1:5]을 행으로 인식해서 슬라이싱이 실행된다.
#[행][열]과 같은 방식으로는 2차원 이상 배열의 슬라이싱이
#불가능하므로 반드시 [행, 열]과 같은 방식을 사용해야 한다.
print(a[1:3][1:5])
print((a[1:3])[1:5])
[[13 14 15 16 17 18]]
[[13 14 15 16 17 18]]
Image('./numpyImages/numpyImage07.jpg', width=800)

#음수 인덱싱을 이용한 법위 지정
#음수 인덱스를 지정한 axis의 마지막 요소로부터
#반대 방향의 인덱스이고 -1은 마지막 요소의 인덱스를
#의미한다.
print(a[1:-1])
print(a[1:-1, 1:-1])
[[ 7 8 9 10 11 12]
[13 14 15 16 17 18]]
[[ 8 9 10 11]
[14 15 16 17]]
#슬라이싱을 이용한 데이터 수정
print(a)
slide_arr = a[1:3, 1:5]
print(slide_arr)
print(slide_arr[:, 1:3])
#슬라이싱의 결과는 원본의 view이므로
#슬라이싱 결과를 수정하면 원본도 같이
#수정이 된다.
slide_arr[:, 1:3] = 9999
print(slide_arr[:, 1:3])
print(slide_arr)
print(a)
[[ 1 2 3 4 5 6]
[ 7 8 9 10 11 12]
[13 14 15 16 17 18]
[19 20 21 22 23 24]]
[[ 8 9 10 11]
[14 15 16 17]]
[[ 9 10]
[15 16]]
[[9999 9999]
[9999 9999]]
[[ 8 9999 9999 11]
[ 14 9999 9999 17]]
[[ 1 2 3 4 5 6]
[ 7 8 9999 9999 11 12]
[ 13 14 9999 9999 17 18]
[ 19 20 21 22 23 24]]
불린 인덱싱 => 전체 데이터에서 특정 조건을 만족하는 데이터를 추출하는 경우 많이 사용된다. 넘파이의 불린 인덱싱은 각 배열 요소의 선택 여부를 True, False로 지정하는 방식이다. => True를 선택한다.
a = np.arange(1,25).reshape(4,6)
print(a)
[[ 1 2 3 4 5 6]
[ 7 8 9 10 11 12]
[13 14 15 16 17 18]
[19 20 21 22 23 24]]
# a배열에서 요소의 값이 짝수인 요소의 총 합계
even_arr = a % 2 #브로드캐스팅
print(even_arr)
#a%2의 결과가 0과 같냐고 물어보는것 또한 브로드캐스팅이다.
even_arr = (a % 2 == 0)
print(even_arr)
[[1 0 1 0 1 0]
[1 0 1 0 1 0]
[1 0 1 0 1 0]
[1 0 1 0 1 0]]
[[False True False True False True]
[False True False True False True]
[False True False True False True]
[False True False True False True]]
print(a[a%2==0])
print(a[even_arr])
[ 2 4 6 8 10 12 14 16 18 20 22 24]
[ 2 4 6 8 10 12 14 16 18 20 22 24]
print(np.sum(a))
print(np.sum(a[a%2==0]))
print(np.sum(a[a%2!=0]))
300
156
144
불링 인덱싱 응용
# pandas 설치
# !pip install pandas
#!pip install pandas
import pandas as pd
#데이터 파일 => 2014년 시애틀 강수량 데이터
# =>./data/Seattle2014.csv
#2014년 시애틀 1우러 평균 강수량?
#판다스의 read_csv()함수로 csv파일을 데이터프레임으로
#읽어들인다. tsv파일도 읽을 수 있다.
rain_in_seattle = pd.read_csv('./data/Seattle2014.csv')
print(type(rain_in_seattle))
rain_in_seattle
<class 'pandas.core.frame.DataFrame'>
| STATION | STATION_NAME | DATE | PRCP | SNWD | SNOW | TMAX | TMIN | AWND | WDF2 | WDF5 | WSF2 | WSF5 | WT01 | WT05 | WT02 | WT03 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | GHCND:USW00024233 | SEATTLE TACOMA INTERNATIONAL AIRPORT WA US | 20140101 | 0 | 0 | 0 | 72 | 33 | 12 | 340 | 310 | 36 | 40 | -9999 | -9999 | -9999 | -9999 |
| 1 | GHCND:USW00024233 | SEATTLE TACOMA INTERNATIONAL AIRPORT WA US | 20140102 | 41 | 0 | 0 | 106 | 61 | 32 | 190 | 200 | 94 | 116 | -9999 | -9999 | -9999 | -9999 |
| 2 | GHCND:USW00024233 | SEATTLE TACOMA INTERNATIONAL AIRPORT WA US | 20140103 | 15 | 0 | 0 | 89 | 28 | 26 | 30 | 50 | 63 | 72 | 1 | -9999 | -9999 | -9999 |
| 3 | GHCND:USW00024233 | SEATTLE TACOMA INTERNATIONAL AIRPORT WA US | 20140104 | 0 | 0 | 0 | 78 | 6 | 27 | 40 | 40 | 45 | 58 | 1 | -9999 | -9999 | -9999 |
| 4 | GHCND:USW00024233 | SEATTLE TACOMA INTERNATIONAL AIRPORT WA US | 20140105 | 0 | 0 | 0 | 83 | -5 | 37 | 10 | 10 | 67 | 76 | -9999 | -9999 | -9999 | -9999 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 360 | GHCND:USW00024233 | SEATTLE TACOMA INTERNATIONAL AIRPORT WA US | 20141227 | 33 | 0 | 0 | 94 | 44 | 49 | 210 | 210 | 112 | 161 | 1 | -9999 | -9999 | -9999 |
| 361 | GHCND:USW00024233 | SEATTLE TACOMA INTERNATIONAL AIRPORT WA US | 20141228 | 41 | 0 | 0 | 67 | 28 | 18 | 50 | 30 | 58 | 72 | 1 | -9999 | -9999 | -9999 |
| 362 | GHCND:USW00024233 | SEATTLE TACOMA INTERNATIONAL AIRPORT WA US | 20141229 | 0 | 0 | 0 | 61 | 6 | 43 | 350 | 350 | 76 | 103 | 1 | -9999 | -9999 | -9999 |
| 363 | GHCND:USW00024233 | SEATTLE TACOMA INTERNATIONAL AIRPORT WA US | 20141230 | 0 | 0 | 0 | 33 | -21 | 36 | 90 | 70 | 63 | 76 | -9999 | -9999 | -9999 | -9999 |
| 364 | GHCND:USW00024233 | SEATTLE TACOMA INTERNATIONAL AIRPORT WA US | 20141231 | 0 | 0 | 0 | 33 | -27 | 30 | 30 | -9999 | 58 | -9999 | -9999 | -9999 | -9999 | -9999 |
365 rows × 17 columns
#2014 시애틀 데이터의 강수량 열(PRCP)의 데이터만 추출한다.
#하나의 열을 '시리즈'라하고 두개 이상의 열이 있다면 프레임이라 한다.
rain_arr = rain_in_seattle['PRCP']
print(type(rain_arr))
#판다스 Series 데이터에 values속성을 지정하면
#넘파이 배열로 변환한다.
rain_arr = rain_in_seattle['PRCP'].values
print(type(rain_arr))
print(rain_arr.shape)
print(rain_arr.ndim)
print(rain_arr)
<class 'pandas.core.series.Series'>
<class 'numpy.ndarray'>
(365,)
1
[ 0 41 15 0 0 3 122 97 58 43 213 15 0 0 0 0 0 0
0 0 0 5 0 0 0 0 0 89 216 0 23 20 0 0 0 0
0 0 51 5 183 170 46 18 94 117 264 145 152 10 30 28 25 61
130 3 0 0 0 5 191 107 165 467 30 0 323 43 188 0 0 5
69 81 277 3 0 5 0 0 0 0 0 41 36 3 221 140 0 0
0 0 25 0 46 0 0 46 0 0 0 0 0 0 5 109 185 0
137 0 51 142 89 124 0 33 69 0 0 0 0 0 333 160 51 0
0 137 20 5 0 0 0 0 0 0 0 0 0 0 0 0 38 0
56 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
18 64 0 5 36 13 0 8 3 0 0 0 0 0 0 18 23 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 3 193 0 0 0 0 0 0 0 0 0 5 0 0
0 0 0 0 0 0 5 127 216 0 10 0 0 0 0 0 0 0
0 0 0 0 0 0 0 84 13 0 30 0 0 0 0 0 0 0
0 0 0 0 0 0 0 5 3 0 0 0 3 183 203 43 89 0
0 8 0 0 0 0 0 0 0 0 0 0 3 74 0 76 71 86
0 33 150 0 117 10 320 94 41 61 15 8 127 5 254 170 0 18
109 41 48 41 0 0 51 0 0 0 0 0 0 0 0 0 0 36
152 5 119 13 183 3 33 343 36 0 0 0 0 8 30 74 0 91
99 130 69 0 0 0 0 0 28 130 30 196 0 0 206 53 0 0
33 41 0 0 0]
days_arr = np.arange(1,366)
print(days_arr[0:40])
condition_jan = days_arr <= 31
print(condition_jan[0:40])
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40]
[ True True True True True True True True True True True True
True True True True True True True True True True True True
True True True True True True True False False False False False
False False False False]
#불린 인덱싱을 이용해 1월의 강수량만 추출한다.
rain_jan = rain_arr[condition_jan]
print(len(rain_jan))
print(rain_jan)
31
[ 0 41 15 0 0 3 122 97 58 43 213 15 0 0 0 0 0 0
0 0 0 5 0 0 0 0 0 89 216 0 23]
print('1월 강수량 합계 : {}'.format(np.sum(rain_jan)))
print('1월 강수량 평균 : {0:5.2f}'.format(np.mean(rain_jan)))
1월 강수량 합계 : 940
1월 강수량 평균 : 30.32
#배열 변환
#베열을 변한하는 방법은 전치, 배열의 shape 변환
#배열 요소 추가 ,배열 결합, 배열 분리 등이 있다.
#전치는 행렬의 인덱스가 바뀌는 것이다.
Image('./numpyImages/numpyImage08.jpg', width=400)
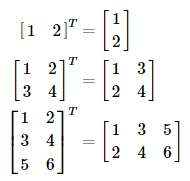
#넘파이에서 배열을 전치하기 위해 배열.T속성을 사용한다.
a = np.arange(1,7).reshape(2,3)
print(a)
#소문자 't'를 사용하면 에러가 발생된다.
print(a.T)
[[1 2 3]
[4 5 6]]
[[1 4]
[2 5]
[3 6]]
#배열 형태 변경
#넘파이는 배열의 shape을 변경하는 reshape() 함수와
#reval()함수를 제공한다.
#reshpae()함수는 데이터 변경없이 지정된 shape으로
#배열의 형태를 변환한다.
#raval()함수는 배열의 shape을 무조건 1차원으로 변환한다.
a = np.random.randint(1,10, (3,4))
print(a)
#단순히 reshape()함수만 실행하면 배열의
#구조가 변경되지 않는다.
print(a.reshape(2,6))
print(a)
#reshpae()함수로 배열의 구조를 변경하려면
#실행 결과를 다시 저장시켜야 한다.
a=a.reshape(2,6)
print(a)
#단순히 ravel()함수만 실행하면 배열의
#구조가 변경되지 않는다.
print(a.ravel())
print(a)
#ravel()함수로 배열의 구조를 변경하려면
#실행 결과를 다시 저장시켜야 한다.
a=a.ravel()
print(a)
[[1 9 3 9]
[6 2 9 2]
[5 6 3 8]]
[[1 9 3 9 6 2]
[9 2 5 6 3 8]]
[[1 9 3 9]
[6 2 9 2]
[5 6 3 8]]
[[1 9 3 9 6 2]
[9 2 5 6 3 8]]
[1 9 3 9 6 2 9 2 5 6 3 8]
[[1 9 3 9 6 2]
[9 2 5 6 3 8]]
[1 9 3 9 6 2 9 2 5 6 3 8]
#ravel()함수도 인덱싱, 슬라이싱의 경우처럼
#원본 배열의 view를 보여준다.
#ravel()함수가 변환한 배열을 수정하면 원본
#배열의 내용이 같이 수정된다.
a = np.random.randint(1,10,(3,4))
print(a)
b = a.ravel()
print(b)
b[0] = 99
print(b)
print(a)
[[2 9 2 8]
[4 5 4 4]
[7 7 5 4]]
[[[2 9]
[2 8]]
[[4 5]
[4 4]]
[[7 7]
[5 4]]]
#reshape()함수도 인덱싱, 슬라이싱의 경우처럼
#원본 배열의 view를 보여준다.
#reshape()함수가 변환한 배열을 수정하면 원본
#배열의 내용이 같이 수정된다.
a = np.random.randint(1,10,(3,4))
print(a)
b = a.reshape(3,2,2)
print(b)
b[1][0][1] = 99
print(b)
print(a)
[[2 5 4 2]
[3 1 7 8]
[7 7 3 1]]
[[[2 5]
[4 2]]
[[3 1]
[7 8]]
[[7 7]
[3 1]]]
[[[ 2 5]
[ 4 2]]
[[ 3 99]
[ 7 8]]
[[ 7 7]
[ 3 1]]]
[[ 2 5 4 2]
[ 3 99 7 8]
[ 7 7 3 1]]
#resize() 함수는 배열의 shape과 크기를 변경한다.
#resize(배열, new_shape), 배열.resize(new_shape)
#resize()와 reshape()함수는 shape을 변경한다는
#부분에서는 동일하지만 reshape()함수는 요소의
#개수가 변경되면 에러가 발생되지만 resize()
#함수는 shape을 변경하는 과정에서 요소의 개수를
#늘이거나 줄일 수 있다.
a = np.random.randint(1,10,(2,6))
print(a)
#resize()함수는 변경된 데이터를 사용하라면
#실행한 결과를 새 배열에 저장시켜 사용해야
#한다.
print(np.resize(a, (6,2)))
print(a)
b = np.resize(a,(6,2))
print(b)
[[1 5 3 7 8 3]
[3 6 9 5 2 2]]
[[1 5]
[3 7]
[8 3]
[3 6]
[9 5]
[2 2]]
[[1 5 3 7 8 3]
[3 6 9 5 2 2]]
[[1 5]
[3 7]
[8 3]
[3 6]
[9 5]
[2 2]]
#요소의 개수가 바뀌는 resize()
a = np.random.randint(1,10,(2,6))
print(a)
#reshape()함수는 원본 요소의 개수와
#reshape()함수로 변경하는 요소의
#개수가 다르면 에러가 발생한다.
#a.reshape(2,10)
#np.resize(배열, new_shape)형식은
#실행 결과 원본 데이터가 변경되지 않기에
#다른 변수에 저장해서 사용한다.
#배열 요소의 개수가 12개에서 20개로 늘어나고
#늘어난 요소에는 원본 내용이 반복되서 채워진다.
b=np.resize(a, (2,10))
print(a)
print(b)
#배열.resize(new_shape)형식은 실행하면 원본 데이터가
#변경되므로 그대로 사용하면 된다.
#배열 요소의 개수가 12개에서 20개로 눌어나고 늘어난
#요소에는 0이 채워진다.
a.resize(2,10)
print(a)
[[3 1 2 3 8 4]
[2 5 6 5 1 8]]
[[3 1 2 3 8 4]
[2 5 6 5 1 8]]
[[3 1 2 3 8 4 2 5 6 5]
[1 8 3 1 2 3 8 4 2 5]]
[[3 1 2 3 8 4 2 5 6 5]
[1 8 0 0 0 0 0 0 0 0]]
a = np.random.randint(1,10,(2,6))
print(a)
#배열 요소의 개수가 12개에서 8개로 줄어들고
#줄어든 요소의 데이터는 분실된다.
b=np.resize(a, (2,4))
print(b)
#배열 요소의 개수가 12개에서 8개로 줄어들고
#줄어든 요소의 데이터는 분실된다.
a.resize(2,4)
print(a)
[[1 5 9 5 1 8]
[9 7 6 8 1 7]]
[[1 5 9 5]
[1 8 9 7]]
[[1 5 9 5]
[1 8 9 7]]
#append()함수는 배열 끝에 데이터(배열)를 추가한다.
#axis로 데이터가 추가되는 방향을 지정할 수 있다.
#np.append(배열, 추가할 데이터, axis)
a = np.arange(1,10).reshape(3,3)
print(a)
b = np.arange(10,19).reshape(3,3)
print(b)
[[1 2 3]
[4 5 6]
[7 8 9]]
[[10 11 12]
[13 14 15]
[16 17 18]]
#axis를 지정하지 않을 경우 배열은 1차원으로 변환된 후 결합된다.
#result = np.append(a,b,axis=None)
result = np.append(a,b)
print(result)
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18]
#axis=0으로 가정한 경우
#배열의 아래쪽에 배열이 추가(열방항)되기 때문에
#행의 개수는 달라도 상관 없지만 열의 개수는 반드시 같아야 한다.
result = np.append(a,b,axis=0)
print(result)
#2차원 배열에서 shape은 행과 열을 의미한다.
print(result.shape)
#행의 개수(2차원에서 shape[0]은 행을 의미)
print(result.shape[0])
#열의 개수(2차원에서 shape[1]은 열을 의미)
print(result.shape[1])
#axis=0으로 설정시 shape[0]은 서로 달라도 상관없지만
#shape[1]은 반드시 같아야 오류가 발생되지 않는다.
c=np.arange(19,31).reshape(4,3)
print(c)
result = np.append(a,c, axis=0)
print(result)
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]
[13 14 15]
[16 17 18]]
(6, 3)
6
3
[[19 20 21]
[22 23 24]
[25 26 27]
[28 29 30]]
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[19 20 21]
[22 23 24]
[25 26 27]
[28 29 30]]
#axis=1으로 가정한 경우
#배열의 오른쪽에 배열이 추가(행방항)되기 때문에
#열의 개수는 달라도 상관 없지만 행의 개수는 반드시 같아야 한다.
result = np.append(a,b,axis=0)
print(result)
#2차원 배열에서 shape은 행과 열을 의미한다.
print(result.shape)
#행의 개수(2차원에서 shape[0]은 행을 의미)
print(result.shape[0])
#열의 개수(2차원에서 shape[1]은 열을 의미)
print(result.shape[1])
#axis=1으로 설정시 shape[1]은 서로 달라도 상관없지만
#shape[0]은 반드시 같아야 오류가 발생되지 않는다.
c=np.arange(19,31).reshape(3,4)
print(c)
result = np.append(a,c, axis=1)
print(result)
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]
[13 14 15]
[16 17 18]]
(6, 3)
6
3
[[19 20 21 22]
[23 24 25 26]
[27 28 29 30]]
[[ 1 2 3 19 20 21 22]
[ 4 5 6 23 24 25 26]
[ 7 8 9 27 28 29 30]]
#insert()함수는 지정된 index위치에 데이터를 삽입한다.
#axis로 데이터가 삽입되는 방향을 지정할 수 있다.
#np.insert(배열, index, 추가할 데이터, axis)
a = np.arange(1,10).reshape(3,3)
print(a)
[[1 2 3]
[4 5 6]
[7 8 9]]
#axis를 지정하지 않으면 1차원 배열로 변환하고
#index위치에 데이터를 삽입한다.
#print(np.insert(a,1,7777,axis=None))
print(np.insert(a,1,7777))
[ 1 7777 2 3 4 5 6 7 8 9]
#axis=0으로 지정하면 열 방향 index전체에 데이터를
#삽입한다.
print(np.insert(a,1,7777,axis=0))
[[ 1 2 3]
[7777 7777 7777]
[ 4 5 6]
[ 7 8 9]]
#axis=1으로 지정하면 행 방향 index전체에 데이터를
#삽입한다.
print(np.insert(a,1,7777,axis=1))
[[ 1 7777 2 3]
[ 4 7777 5 6]
[ 7 7777 8 9]]
#delete() 함수는 지정된 index의 데이터를 삭제한다.
#axis로 데이터가 삭제되는 방향을 지정할 수 있다.
#delete(배열, index, axis)
a = np.arange(1,10).reshape(3,3)
print(a)
#axis를 지정하지 않으면 1차워 배열로 변호나하고
#index번째 데이터를 삭제한다.
#print(np.delete(a,1,axis=None))
print(np.delete(a,1))
[[1 2 3]
[4 5 6]
[7 8 9]]
[1 3 4 5 6 7 8 9]
#axis=0으로 지정하면 열 방향으로 index 위치의
#데이터가 삭제된다.
print(np.delete(a,1,axis=0))
[[1 2 3]
[7 8 9]]
#axis=0으로 지정하면 열 방향으로 index 위치의
#데이터가 삭제된다.
print(np.delete(a,1,axis=1))
[[1 3]
[4 6]
[7 9]]
#배열 분리
#넘파이는 배열을 수평 방향으로 분할하는
#hsplit()함수와 수직 방향으로 분할하는
#vsplit()함수를 제공한다.
#hsplit() 함수로 배열을 수평 방향으로 분할한다.
#np.hsplit(배열, 분할할 배열의 개수)
#분할할 배열의 개수에 리스트로 분할할 인덱스를 지정할 수 있다.
#np.hsplit(배열, [분할할 인덱스])
a = np.arange(1,25).reshape(4,6)
print(type(a))
print(a)
#hsplit()함수의 실행 결과는 넘파이 배열이
#저장된 파이썬 리스트이다.
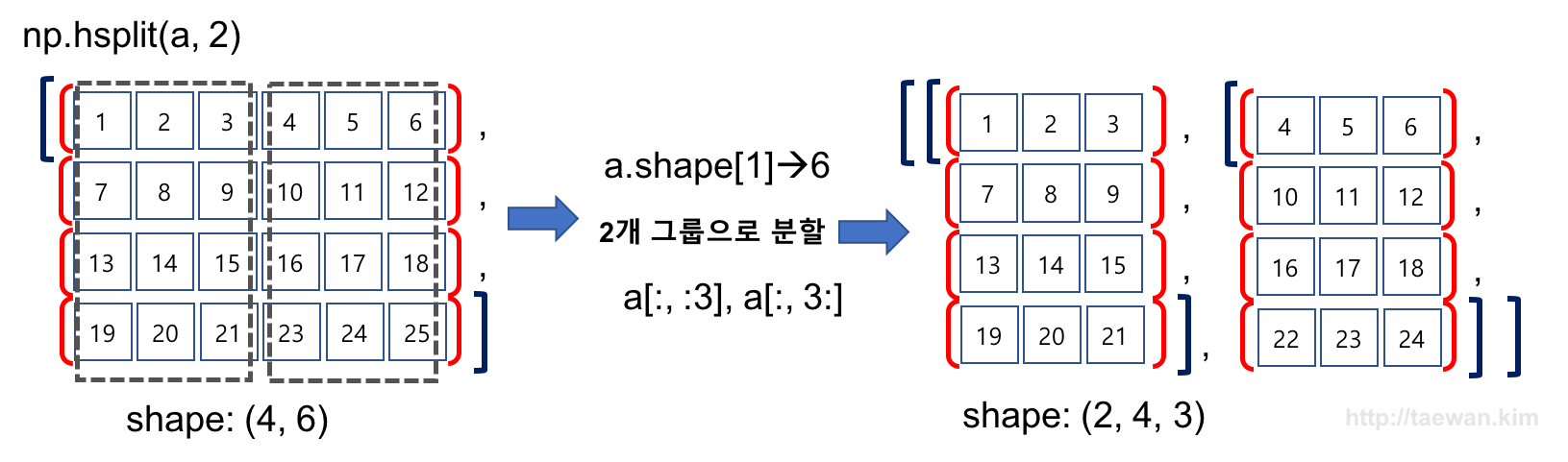
result = np.hsplit(a, 2)
print(result)
#<class 'list'>
print(type(result))
#<class 'numpy.ndarray'>
print(type(result[0]))
print(result[0])
Image('./numpyImages/numpyImage09.jpg', width=800)
<class 'numpy.ndarray'>
[[ 1 2 3 4 5 6]
[ 7 8 9 10 11 12]
[13 14 15 16 17 18]
[19 20 21 22 23 24]]
[array([[ 1, 2, 3],
[ 7, 8, 9],
[13, 14, 15],
[19, 20, 21]]), array([[ 4, 5, 6],
[10, 11, 12],
[16, 17, 18],
[22, 23, 24]])]
<class 'list'>
<class 'numpy.ndarray'>
[[ 1 2 3]
[ 7 8 9]
[13 14 15]
[19 20 21]]
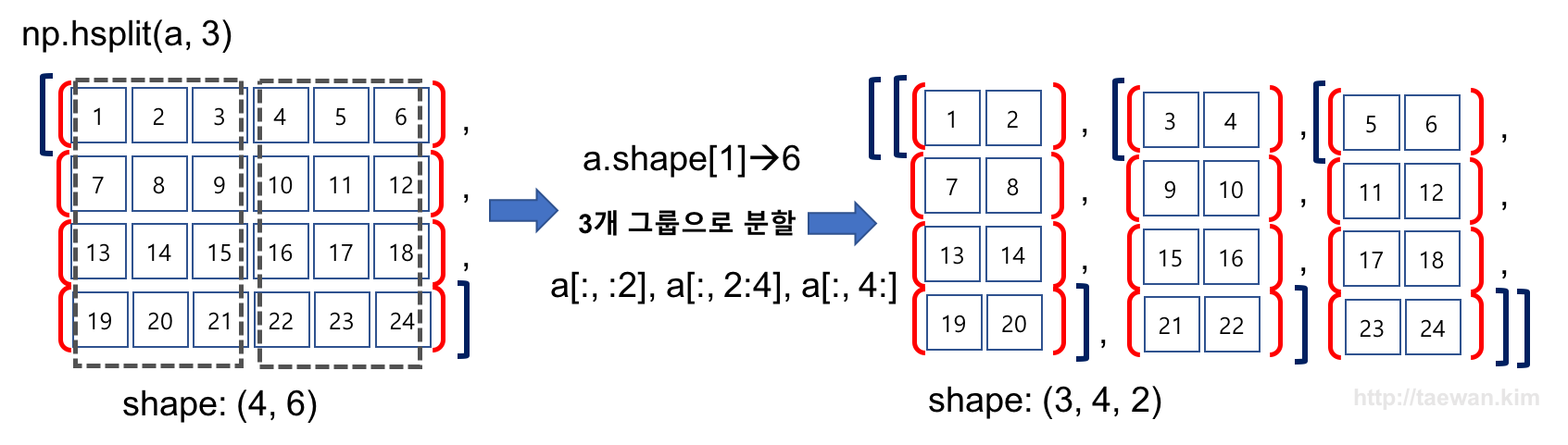
result = np.hsplit(a, 3)
#<class 'list'>
print(type(result))
print(result)
#<class 'numpy.ndarray'>
print(type(result[0]))
print(result[0])
Image('./numpyImages/numpyImage10.jpg', width=800)
<class 'list'>
[array([[ 1, 2],
[ 7, 8],
[13, 14],
[19, 20]]), array([[ 3, 4],
[ 9, 10],
[15, 16],
[21, 22]]), array([[ 5, 6],
[11, 12],
[17, 18],
[23, 24]])]
<class 'numpy.ndarray'>
[[ 1 2]
[ 7 8]
[13 14]
[19 20]]
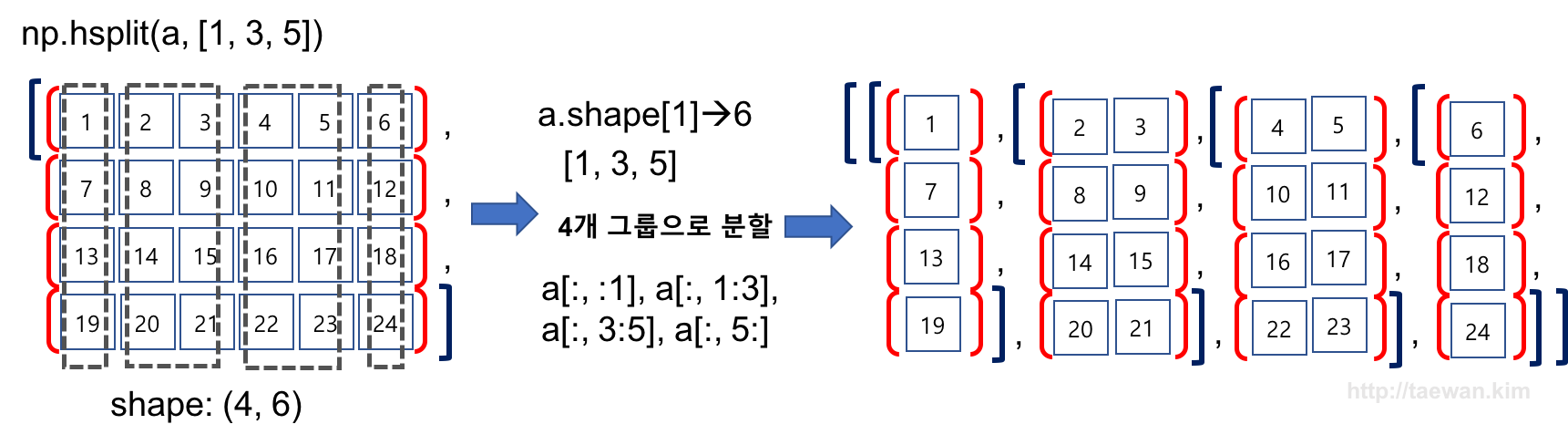
result = np.hsplit(a, [1,3,5])
#<class 'list'>
print(type(result))
print(result)
#<class 'numpy.ndarray'>
print(type(result[0]))
print(result[0])
Image('./numpyImages/numpyImage11.jpg', width=800)
<class 'list'>
[array([[ 1],
[ 7],
[13],
[19]]), array([[ 2, 3],
[ 8, 9],
[14, 15],
[20, 21]]), array([[ 4, 5],
[10, 11],
[16, 17],
[22, 23]]), array([[ 6],
[12],
[18],
[24]])]
<class 'numpy.ndarray'>
[[ 1]
[ 7]
[13]
[19]]
#vsplit() 함수로 배열을 수평 방향으로 분할한다.
#np.vsplit(배열, 분할할 배열의 개수)
#분할할 배열의 개수에 리스트로 분할할 인덱스를 지정할 수 있다.
#np.vsplit(배열, [분할할 인덱스])
a = np.arange(1,25).reshape(4,6)
print(a)
#hsplit()함수의 실행 결과는 넘파이 배열이
#저장된 파이썬 리스트이다.
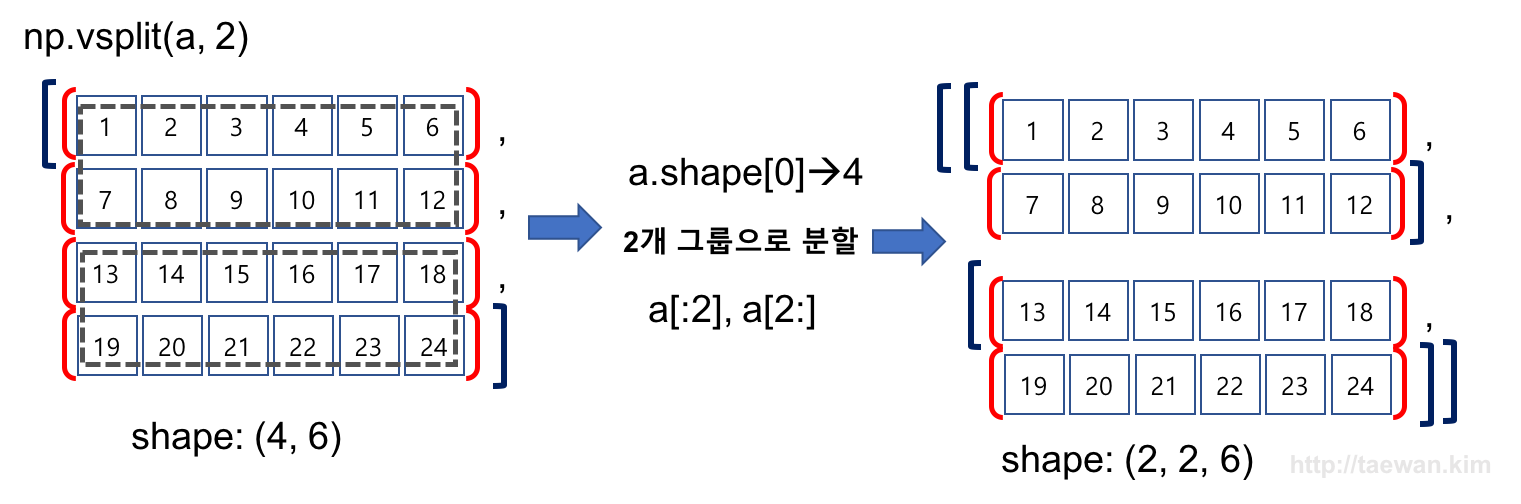
result = np.vsplit(a, 2)
print(result)
#<class 'list'>
print(type(result))
#<class 'numpy.ndarray'>
print(type(result[0]))
print(result[0])
Image('./numpyImages/numpyImage12.jpg', width=800)
[[ 1 2 3 4 5 6]
[ 7 8 9 10 11 12]
[13 14 15 16 17 18]
[19 20 21 22 23 24]]
[array([[ 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12]]), array([[13, 14, 15, 16, 17, 18],
[19, 20, 21, 22, 23, 24]])]
<class 'list'>
<class 'numpy.ndarray'>
[[ 1 2 3 4 5 6]
[ 7 8 9 10 11 12]]
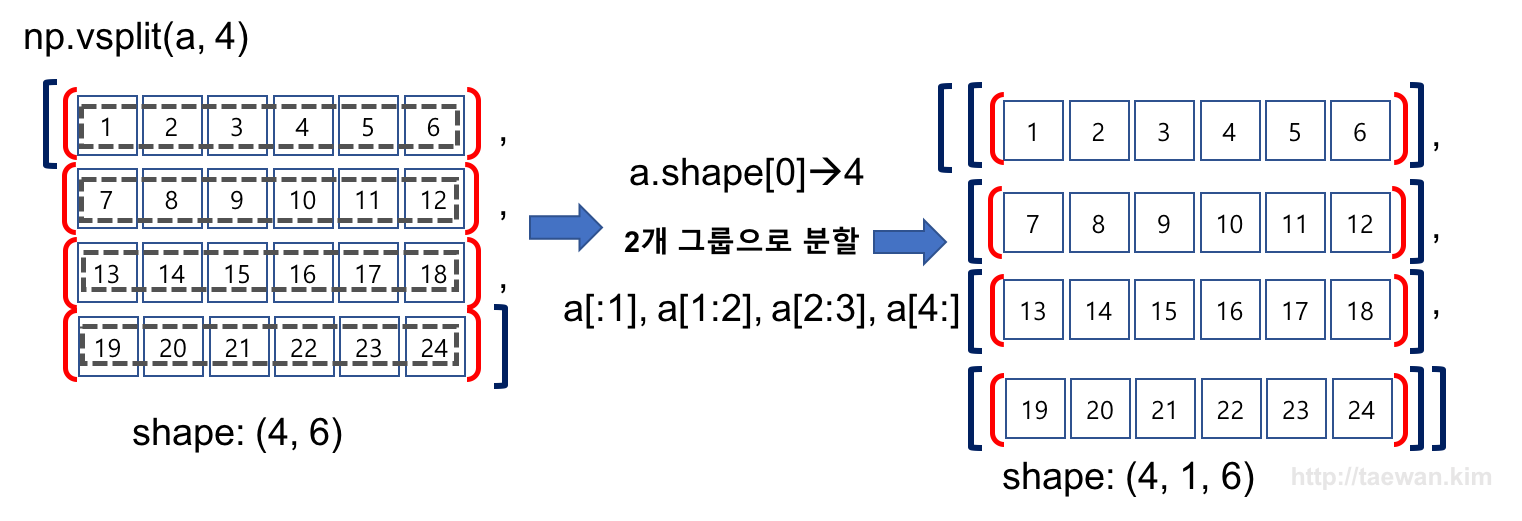
result = np.vsplit(a, 4)
print(result)
#<class 'list'>
print(type(result))
#<class 'numpy.ndarray'>
print(type(result[0]))
print(result[0])
Image('./numpyImages/numpyImage13.jpg', width=800)
[array([[1, 2, 3, 4, 5, 6]]), array([[ 7, 8, 9, 10, 11, 12]]), array([[13, 14, 15, 16, 17, 18]]), array([[19, 20, 21, 22, 23, 24]])]
<class 'list'>
<class 'numpy.ndarray'>
[[1 2 3 4 5 6]]
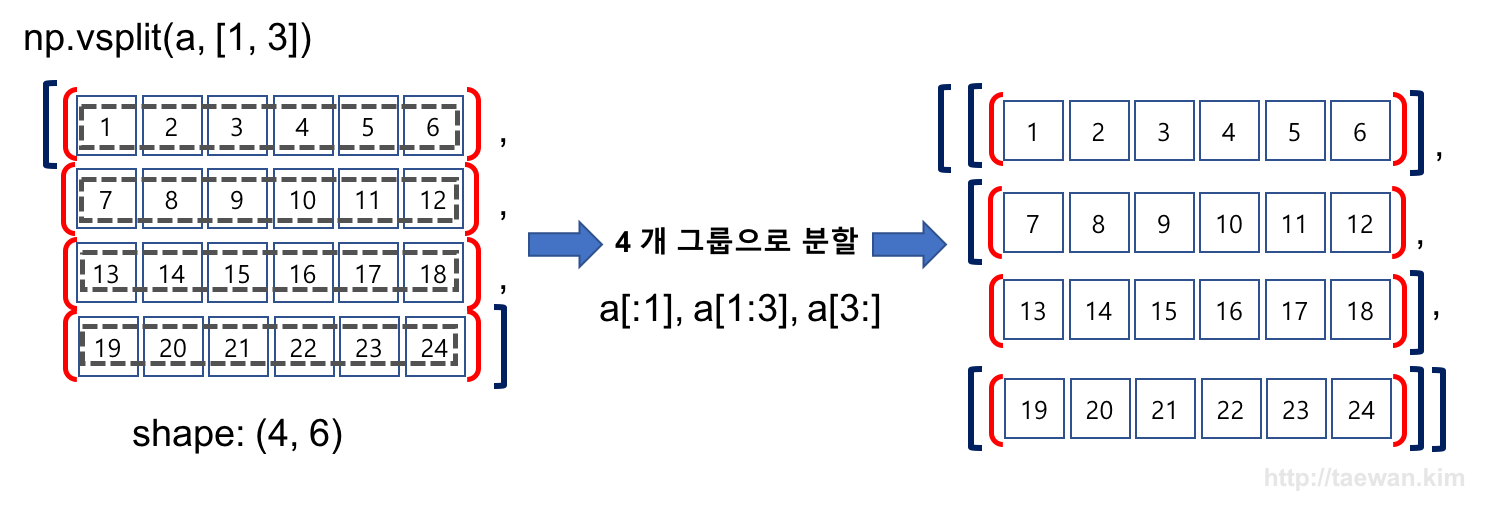
result = np.vsplit(a, [1,3])
print(result)
#<class 'list'>
print(type(result))
#<class 'numpy.ndarray'>
print(type(result[0]))
print(result[0])
Image('./numpyImages/numpyImage14.jpg', width=800)
[array([[1, 2, 3, 4, 5, 6]]), array([[ 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18]]), array([[19, 20, 21, 22, 23, 24]])]
<class 'list'>
<class 'numpy.ndarray'>
[[1 2 3 4 5 6]]
댓글남기기