5_판다스1
import warnings
warnings.filterwarnings('ignore')
from IPython.display import Image
import numpy as np
import pandas as pd
데이터 분석을 하기 위해 가장 먼저 해야 할 일은 데이터를 불러오는 일이다 =>불러온 데이터를 데이터 집합(set)이라고 한다.
#read_csv()함수로 갭마인더 데이터 집합을 불러와서
#데이터프레임으로 리턴한다.
#read_csv()함수는 기본적으로 ','로 구분된 csv데이터를
#불러오기 때문에, tab으로 구분된 tsv데이터는 sep옵션
#'\t'를 지정해서 불러와야 한다.
gapminder_df = pd.read_csv('./data/gapminder.tsv', sep='\t')
print(type(gapminder_df))
gapminder_df
#country : 국가, continent : 대륙, year : 년도
#liefExp : 평균 수명, pop : 인구수, gdpPercap : 1인당 gdp
<class 'pandas.core.frame.DataFrame'>
| country | continent | year | lifeExp | pop | gdpPercap | |
|---|---|---|---|---|---|---|
| 0 | Afghanistan | Asia | 1952 | 28.801 | 8425333 | 779.445314 |
| 1 | Afghanistan | Asia | 1957 | 30.332 | 9240934 | 820.853030 |
| 2 | Afghanistan | Asia | 1962 | 31.997 | 10267083 | 853.100710 |
| 3 | Afghanistan | Asia | 1967 | 34.020 | 11537966 | 836.197138 |
| 4 | Afghanistan | Asia | 1972 | 36.088 | 13079460 | 739.981106 |
| ... | ... | ... | ... | ... | ... | ... |
| 1699 | Zimbabwe | Africa | 1987 | 62.351 | 9216418 | 706.157306 |
| 1700 | Zimbabwe | Africa | 1992 | 60.377 | 10704340 | 693.420786 |
| 1701 | Zimbabwe | Africa | 1997 | 46.809 | 11404948 | 792.449960 |
| 1702 | Zimbabwe | Africa | 2002 | 39.989 | 11926563 | 672.038623 |
| 1703 | Zimbabwe | Africa | 2007 | 43.487 | 12311143 | 469.709298 |
1704 rows × 6 columns
#판다스 head()함수로 데이터프레임의 앞쪽
#데이터를 지정한 개수만큼 얻어온다.
#=>기본값은 5개
gapminder_df.head(3)
| country | continent | year | lifeExp | pop | gdpPercap | |
|---|---|---|---|---|---|---|
| 0 | Afghanistan | Asia | 1952 | 28.801 | 8425333 | 779.445314 |
| 1 | Afghanistan | Asia | 1957 | 30.332 | 9240934 | 820.853030 |
| 2 | Afghanistan | Asia | 1962 | 31.997 | 10267083 | 853.100710 |
#판다스 tail()함수로 데이터프레임의 앞쪽
#데이터를 지정한 개수만큼 얻어온다.
#=>기본값은 5개
gapminder_df.tail(3)
| country | continent | year | lifeExp | pop | gdpPercap | |
|---|---|---|---|---|---|---|
| 1701 | Zimbabwe | Africa | 1997 | 46.809 | 11404948 | 792.449960 |
| 1702 | Zimbabwe | Africa | 2002 | 39.989 | 11926563 | 672.038623 |
| 1703 | Zimbabwe | Africa | 2007 | 43.487 | 12311143 | 469.709298 |
#판다스의 shape속성은 데이터프레임이 가지고 있는
#데이터의 행과 열에 대한 정보를 저장하고 있다.
print(gapminder_df.shape)
#shape[0]은 데이터프레임의 행의 개수를 저장하고
#있다. => 데이터의 개수
print(gapminder_df.shape[0])
#shape[1]은 데이터프레임의 열의 개수를 저장하고
#있다. => 데이터의 개수
print(gapminder_df.shape[1])
#판다스의 columns 속성은 데이터프레임을 구성하는
#열(필드명,속성,변수)이름을 저장하고 있다.
print(gapminder_df.columns)
(1704, 6)
1704
6
Index(['country', 'continent', 'year', 'lifeExp', 'pop', 'gdpPercap'], dtype='object')
#판다스의 dtypes 속성은 데이터프레임을 구성하고 있는 데이터의 자료형을
#확인할 수 있다. object => 문자열
print(gapminder_df.dtypes)
country object
continent object
year int64
lifeExp float64
pop int64
gdpPercap float64
dtype: object
#판다스의 info()함수를 사용면 dtypes 속송을 사용한 것 보다
#조금 더 자세한 내용을 확인할 수 있다.
print(gapminder_df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1704 entries, 0 to 1703
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 country 1704 non-null object
1 continent 1704 non-null object
2 year 1704 non-null int64
3 lifeExp 1704 non-null float64
4 pop 1704 non-null int64
5 gdpPercap 1704 non-null float64
dtypes: float64(2), int64(2), object(2)
memory usage: 80.0+ KB
None
열 단위 데이터 추출하기
#데이터프레임에서 데이터를 열 단위로 추출하려면 대괄호와
#열이름을 사용하며 추축한 열은 변수에 저장해서 사용한다.
#한개의 열만 추출하면 시리즈를 얻을 수 있다.
#데이터프레임에서 한개의 열만 얻어오려면 열 이름만
#사용하면 된다.
country_df = gapminder_df['country']
print(type(country_df))
print(country_df.head(3))
print(country_df.tail(3))
#gapminder_df['year']
#gapminder_df['pop']
<class 'pandas.core.series.Series'>
0 Afghanistan
1 Afghanistan
2 Afghanistan
Name: country, dtype: object
1701 Zimbabwe
1702 Zimbabwe
1703 Zimbabwe
Name: country, dtype: object
#2개 이상의 열을 추출하면 데이터프레임으로 얻어올 수 있다.
#데이터프레임에서 한개의 열만 얻어오려면 []안에 열 이름만
#적어주만 되지면 두개 이상의 열을 얻어오려면 []안에 반드시
#리스트 형태로 이름을 적어주어야 한다.
sub_set = gapminder_df[['country', 'continent', 'year']]
print(type(sub_set))
<class 'pandas.core.frame.DataFrame'>
sub_set.head(3)
| country | continent | year | |
|---|---|---|---|
| 0 | Afghanistan | Asia | 1952 |
| 1 | Afghanistan | Asia | 1957 |
| 2 | Afghanistan | Asia | 1962 |
sub_set.tail(3)
| country | continent | year | |
|---|---|---|---|
| 1701 | Zimbabwe | Africa | 1997 |
| 1702 | Zimbabwe | Africa | 2002 |
| 1703 | Zimbabwe | Africa | 2007 |
#행 단위 데이터 추출하기
#loc는 인덱스를 기준으로 행 단위 데이터를 추출하고
#iloc는 행 번호를 기준으로 행 단위 데이트를 추출한다.
#head()함수를 실행했을 때 맨 왼쪽에 보이는 숫자가 인덱스를
#인덱스를 의미하고 행 번호는 데이터 순서를 뜻한다.
gapminder_df.head(3)
| country | continent | year | lifeExp | pop | gdpPercap | |
|---|---|---|---|---|---|---|
| 0 | Afghanistan | Asia | 1952 | 28.801 | 8425333 | 779.445314 |
| 1 | Afghanistan | Asia | 1957 | 30.332 | 9240934 | 820.853030 |
| 2 | Afghanistan | Asia | 1962 | 31.997 | 10267083 | 853.100710 |
#loc를 사용하면 0~1703사이의 값을 이용해 행 단위의 데이터를
#추출할 수 있고 범위를 벗어나는 -1이나 1704같이 인덱스를
#지정하면 에러가 발생된다.
print(gapminder_df.loc[0])
print(gapminder_df.loc[1703])
country Afghanistan
continent Asia
year 1952
lifeExp 28.801
pop 8425333
gdpPercap 779.445
Name: 0, dtype: object
country Zimbabwe
continent Africa
year 2007
lifeExp 43.487
pop 12311143
gdpPercap 469.709
Name: 1703, dtype: object
#마지막 데이터 추출하기
#shape[0]에 전체 행의 개수가 저장되어 있는 것을 이용한다.
#print(gapminder_df.loc[-1]) #에러, loc는 음수 인덱싱이 지원되지 않는다.
print(gapminder_df.shape[0])
print(gapminder_df.loc[gapminder_df.shape[0]-1])
#tail()함수를 이용한다.
print(gapminder_df.tail(1))
1704
country Zimbabwe
continent Africa
year 2007
lifeExp 43.487
pop 12311143
gdpPercap 469.709
Name: 1703, dtype: object
country continent year lifeExp pop gdpPercap
1703 Zimbabwe Africa 2007 43.487 12311143 469.709298
#여러 인덱스의 데이터를 한꺼번에 추출하려면 리스트에 추출하려는
#데이터의 인덱스를 담아서loc로 넘겨준다.
print(gapminder_df.loc[[0, 99, 999]])
country continent year lifeExp pop gdpPercap
0 Afghanistan Asia 1952 28.801 8425333 779.445314
99 Bangladesh Asia 1967 43.453 62821884 721.186086
999 Mongolia Asia 1967 51.253 1149500 1226.041130
#loc는 location을 생각하자
#iloc를 사용하면 0~1703사이의 값을 이용해 행 단위의 데이터를 추출할 수 있고
#1704와 같이 범위를 벗어나는 행 번호를 사용하면 에러가 발생한다.
#iloc는 음수를 지정하면 뒤 부터 역순으로 행 단위 데이터를 추출할 수 있다.
#(음수 인덱싱을 지원한다.)
print(gapminder_df.iloc[0])
print(gapminder_df.iloc[1703])
#print(gapminder_df.iloc[1704])하면 에러가 발생된다.
print(gapminder_df.iloc[-1])
print(gapminder_df.iloc[[0, 99, 999]])
country Afghanistan
continent Asia
year 1952
lifeExp 28.801
pop 8425333
gdpPercap 779.445
Name: 0, dtype: object
country Zimbabwe
continent Africa
year 2007
lifeExp 43.487
pop 12311143
gdpPercap 469.709
Name: 1703, dtype: object
country Zimbabwe
continent Africa
year 2007
lifeExp 43.487
pop 12311143
gdpPercap 469.709
Name: 1703, dtype: object
country continent year lifeExp pop gdpPercap
0 Afghanistan Asia 1952 28.801 8425333 779.445314
99 Bangladesh Asia 1967 43.453 62821884 721.186086
999 Mongolia Asia 1967 51.253 1149500 1226.041130
#loc와 iloc를 자유자재로 사용하려면 추추할 데이터의
#행과 열을 지정하는 방법을 알아야 한다.
#데이터프레임.loc[행, 열],
#데이터프레임.iloc[행, 열]
#위와 같은 방법을 사용하며 행과 열은 슬라이싱이나
#range()함수를 사용하는 방법이 있다.
#슬라이싱
#모든행(':')의 데이터에 대해 country, year,pop열을 추출한다.
#import pandas as pd
#gapminder_df = pd.read_csv('./data/gapminder.tsv', sep='\t')
#loc는 열을 추출할 때 열 이름을 문자열 지정해서 얻어온다.
sub_set = gapminder_df.loc[:,['country','year','pop']]
#loc는 열을 추출할 때 열 인덱스를 지정하면 에러가 발생된다.
#sub_set = gapminder_df.loc[:,[0,2,4]] => 에러발생
#한개의 열만 가져올 경우 시리즈로 나와서 출력 결과가 안이쁘다.
#열의 나열 순서대로 나오는 결과의 열의 순사가 보여진다..
sub_set.head(3)
| country | year | pop | |
|---|---|---|---|
| 0 | Afghanistan | 1952 | 8425333 |
| 1 | Afghanistan | 1957 | 9240934 |
| 2 | Afghanistan | 1962 | 10267083 |
#iloc는 열을 추출할 때 열 이름을 문자열 지정하면 에러가 발생된다..
#sub_set = gapminder_df.iloc[:,['country','year','pop']] => 에러발생
#import pandas as pd
#gapminder_df = pd.read_csv('./data/gapminder.tsv', sep='\t')
#iloc는 열을 추축할 때 열의 인덱스를 지정해서 얻온다.
sub_set = gapminder_df.iloc[:,[0,2,4]]
sub_set.head(3)
| country | year | pop | |
|---|---|---|---|
| 0 | Afghanistan | 1952 | 8425333 |
| 1 | Afghanistan | 1957 | 9240934 |
| 2 | Afghanistan | 1962 | 10267083 |
#range()함수
#range()함수는 초기치부터 최종치를 넘어가지 않을 때 까지
#증가치 만큼 증가하는 숫자 리스트를 만든다.
#range([초기치,]최종치[,증가치])
#초기치가 생략되면 0이, 증가치가 생략되면 1이 가본값이 된다.
#range(10), range(0,10) range(0,10,1)은 모두 같은 표현이다.
print(range(10))
#list()가 리스트의 생성자 함수이다.
print(list(range(0,10,1)))
range(0, 10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
#import pandas as pd
#gapminder_df = pd.read_csv('./data/gapminder.tsv', sep='\t')
sub_set = gapminder_df.iloc[:, range(0,6,2)]
sub_set.head(3)
| country | year | pop | |
|---|---|---|---|
| 0 | Afghanistan | 1952 | 8425333 |
| 1 | Afghanistan | 1957 | 9240934 |
| 2 | Afghanistan | 1962 | 10267083 |
#range()함수보다 더 간편하게 사용할 수 있는 슬라이싱을 이용하는
#것이 편리하다.
sub_set = gapminder_df.iloc[:, ::2]
sub_set.head(3)
| country | year | pop | |
|---|---|---|---|
| 0 | Afghanistan | 1952 | 8425333 |
| 1 | Afghanistan | 1957 | 9240934 |
| 2 | Afghanistan | 1962 | 10267083 |
#iloc로 열 리스트를 정수로 전달하는 방법이 간단해 보일 수 있지만
#이렇게 작성한 코드는 나중에 어떤 데이터를 추출하기 위한 코드인지
#파악하지 못 할 수 있다.
#그래서 보통 loc로 열 리스트에 열 이름을 전달하는 방법을
#일반적으로 사용한다.
기초적인 통계 계산하기
#groupby()함수를 사용해 year 열을 그룹화하고 평균 수명 열(lifeExp)만
#각 국가마다 1952년 당시의 평균 수명의 값을 가져와 그것들의 평균치를 낸다.
#이후 5년 단위로 위와같은 작업을 반복한다.
#추출한 후 평균(mean())을 게산한다.
#그룹화 된 데이터에는 loc, iloc를 사용하지 못한다.
#import pandas as pd
#gapminder_df = pd.read_csv('./data/gapminder.tsv', sep='\t')
#gapminder_df.groupby('year')
print(gapminder_df.groupby('year'))
print(gapminder_df.groupby('year')['lifeExp'])
print(gapminder_df.groupby('year')['lifeExp'].mean())
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001ED7EF8F2B0>
<pandas.core.groupby.generic.SeriesGroupBy object at 0x000001ED7EF8FBA8>
year
1952 49.057620
1957 51.507401
1962 53.609249
1967 55.678290
1972 57.647386
1977 59.570157
1982 61.533197
1987 63.212613
1992 64.160338
1997 65.014676
2002 65.694923
2007 67.007423
Name: lifeExp, dtype: float64
#그래프를 그리기 위한 임포트
import matplotlib.pyplot as plt
global_yearly_life = gapminder_df.groupby('year')['lifeExp'].mean()
#간단한 차트를 그리기 위한것이 plot()이다.
global_yearly_life.plot()
plt.show()
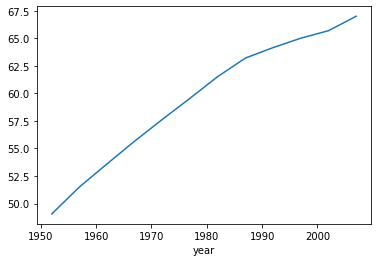
#그룹화의 예시
#칼럼값(year)에서 같은 1952와 관련된 데이터를 하나로 묶는다.
#(브로드캐스팅을 이용하 불린 인덱싱)
gapminder_df[gapminder_df['year'] == 1952]
| country | continent | year | lifeExp | pop | gdpPercap | |
|---|---|---|---|---|---|---|
| 0 | Afghanistan | Asia | 1952 | 28.801 | 8425333 | 779.445314 |
| 12 | Albania | Europe | 1952 | 55.230 | 1282697 | 1601.056136 |
| 24 | Algeria | Africa | 1952 | 43.077 | 9279525 | 2449.008185 |
| 36 | Angola | Africa | 1952 | 30.015 | 4232095 | 3520.610273 |
| 48 | Argentina | Americas | 1952 | 62.485 | 17876956 | 5911.315053 |
| ... | ... | ... | ... | ... | ... | ... |
| 1644 | Vietnam | Asia | 1952 | 40.412 | 26246839 | 605.066492 |
| 1656 | West Bank and Gaza | Asia | 1952 | 43.160 | 1030585 | 1515.592329 |
| 1668 | Yemen, Rep. | Asia | 1952 | 32.548 | 4963829 | 781.717576 |
| 1680 | Zambia | Africa | 1952 | 42.038 | 2672000 | 1147.388831 |
| 1692 | Zimbabwe | Africa | 1952 | 48.451 | 3080907 | 406.884115 |
142 rows × 6 columns
댓글남기기